为什么要整理这种?
只有能讲出来和写出来的东西才是自己的,此文章为 Linux 日常操作指南。 快捷操作 -> 装x必备
你说你懂 Linux,其实大家都懂点,连测试和前端可能都经常打点命令去压测或者部署测试什么的,那你如何证明你更熟悉,来用熟练的快捷操作让旁边观摩的人暗暗惊叹吧~
命令行光标移动指令
光标快速切换到行首尾
1 | ctrl a 行首 |
删除至行尾 | 清除当前光标位置之前的一个单词
1 | ctrl k 可以将当前光标位置之后的所有部分快速清除 |
删除此条命令行
1 | ctrl u 可以直接将整行命令直接清除 |
左|右 移动一个单词
1 | esc b 左移一个单词 |
vim 常用记录
光标漫游
1 | j 向下 |
复制 / 剪切
1 | yy 复制一行 |
删除 / 粘贴
1 | dd 删除一行 |
ctrl + v 块模式
1 | # 举个例子 |
命令行模式
1 | # 在普通模式下,输入 : 即可进入 |
查找字符串
1 | # 在普通模式下,按下/直接进入查找 |
宏录制
一般不咋用,用上了还挺酷的,算是 vim 特有操作
1 | 1. 按下 gg 到行首 |
其他操作
1 | r 替换字符 |
sed 常用记录
常用替换模式(更高级的我很少用)
1 | sed '/^txt/s/a/b/g' file |
示范例子
1 | 统计文件中有每个单词出现了多少次 |
awk 常用记录
常用文本筛选功能 (比如做一些日志处理和统计)
1 | awk -F "," '/^a/' {print $1} file |
示范例子
1 | 外网连接数,根据ip分组 |
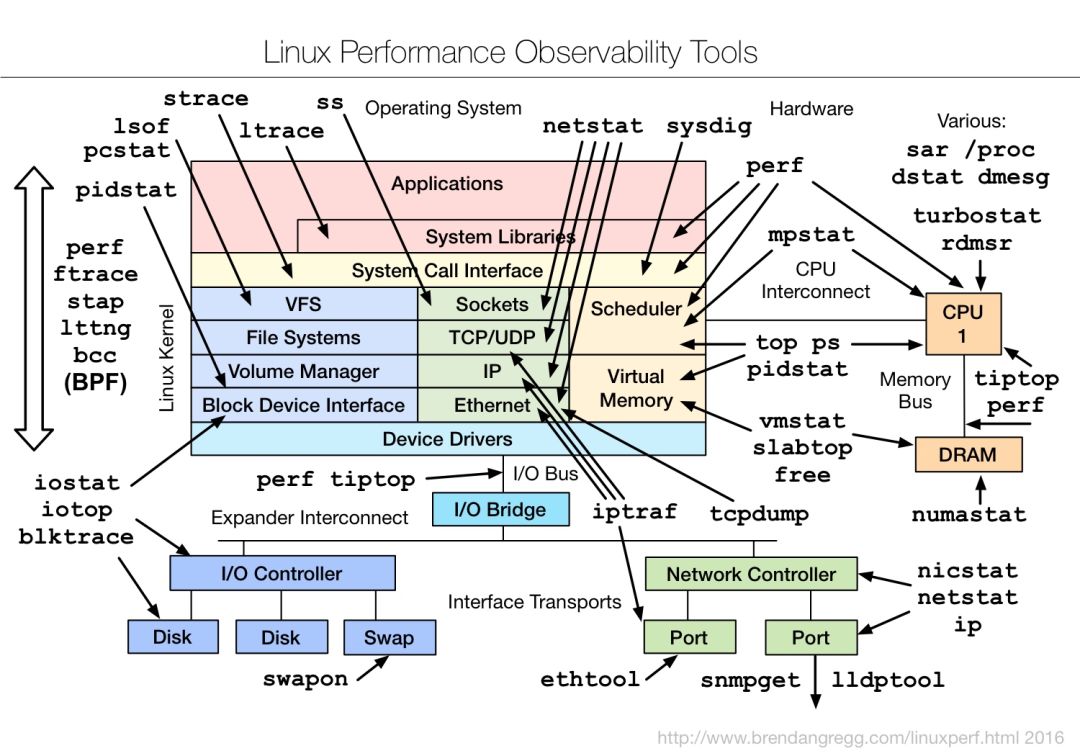
Linux 运维一定要懂得命令
CPU
使用
top查看cpu的load,使用 shift+p 按照 cpu 排序。需要了解 wa,us 等都是什么意思
使用
uptime查看系统启动时间和load什么算是系统过载 ?(服务所收到的请求量原大于它能处理的请求,load值需跟核心数做对比)
ps命令勃大茎深,除了查进程号外,你还需要知道R、S、D、T、Z、<、N状态位的含义top和ps很多功能是相通的,比如watch "ps -mo %cpu,%mem,pid,ppid,command ax"相当于top的进程列表;top -n 1 -bc和ps -ef的结果相似。有生就有死,可以用
kill杀死进程。对java来说,需要关注
kill -9、kill -15、kill -3的含义,kill的信号太多了,可以用kill -l查看,搞懂大多数信号大有裨益。如果暂时不想死,可以通过
&符号在后台执行,比如tail -f a.log &。jobs命令可以查看当前后台的列表,想恢复的话,使用fg回到幕前。这都是终端作业,当你把
term关了你的后台命令也会跟着消失,所以想让你的程序继续执行的话,需要nohup命令,此命令需要牢记
1 | top 中的 wa 是指当CPU空闲且磁盘IO阻塞的时间占比。注意这里只统计磁盘IO,不包含网络IO |
内存
free -m命令,了解free、used、cached、swap各项的含义cat /proc/meminfo查看更详细的内存信息
细心的朋友可能注意到,CPU和内存的信息,通过top等不同的命令显示的数值是一样的。
slabtop用来显示内核缓存占用情况,比如遍历大量文件造成缓存目录项。曾在生产环境中遇到因执行
find /造成dentry_cache耗尽服务器内存。vmstat命令是我最喜欢也最常用的命令之一,可以以最快的速度了解系统的运行状况。每个参数的意义都要搞懂。
swapon、swapoff 开启,关闭交换空间
sar 又一统计类轮子,一般用作采样工具
存储
- 使用
df -h查看系统磁盘使用概况 - lsblk 列出块设备信息
- du 查看目录或者文件大小
网络
rsync 强大的同步工具,可以增量哦
netstat 查看Linux中网络系统状态信息,各种
ss 它能够显示更多更详细的有关TCP和连接状态的信息,而且比netstat更快速更高效。
curl、wget 模拟请求工具、下载工具。
如wget -r https://baidu.com 将下载整个站点
ab Apache服务器的性能测试工具
ifstat 统计网络接口流量状态
nslookup 查询域名DNS信息的工具,在内网根据ip查询域名是爽爆了
nc 网络工具中的瑞士军刀,不会用真是太可惜了
arp 可以显示和修改IP到MAC转换表
traceroute 显示数据包到主机间的路径,俗称几跳,跳的越少越快
tcpdump 不多说了,去下载 wireshark了
网络方面推荐安装体验一下kali Linux(有很多渗透工具,界面UI也很有安全【黑客】风格),上面的工具会让你 high 到极点。
上面资源的组合途径
/proc文件系统是一个伪文件系统,它只存在内存当中,而不占用外存空间。只不过以文件系统的方式为访问系统内核数据的操作提供接口。系统的所有状态都逃不过它的火眼金睛。例如:
cat /proc/vmstat看一下,是不是和vmstat命令的输出很像?cat /proc/meminfo是不是最全的内存信息cat /proc/slabinfo这不就是slabtop的信息么cat /proc/devices已经加载对设备们cat /proc/loadavgload avg原来就躺在这里啊cat /proc/stat所有的CPU活动信息ls /proc/$pid/fd静静地躺着lsof的结果
以 java 应用为例:
举个例子:
怎么查看某个Java进程里面占用CPU最高的一个线程具体信息?
获取进程中占用CPU最高的线程,计为n。
- 使用 top
top -H -p pid,肉眼观察之 - 使用 ps
ps -mo spid,lwp,stime,time,%cpu -p pid
- 使用 top
将线程号转化成十六进制
printf 0x%x n使用 jstack 找到相应进程,打印线程后的100行信息
jstack -l pid| grep spid -A 100
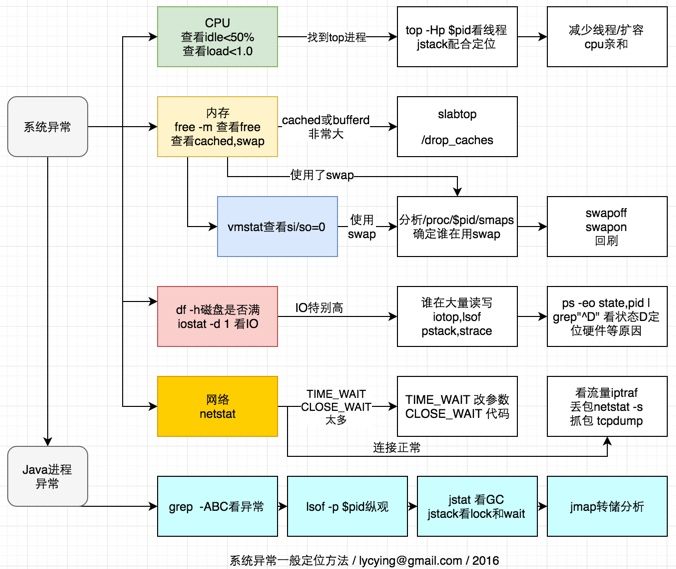
最后附上经典一图